Arrow-rs Parquet 读取中的延迟物化(Late Materialization)实战深度解析
Published
11 Dec 2025
By
Qiwei Huang and Andrew Lamb
Translations
原文(English)
本文深入探讨了在 arrow-rs(为 Apache DataFusion 等项目提供动力的读取器)的 Apache Parquet 读取器中实现延迟物化(Late Materialization)的决策和陷阱。我们将看到一个看似简单的文件读取器如何通过复杂的逻辑来评估谓词——实际上它自身变成了一个微型查询引擎。
1. 为什么要延迟物化?
列式读取是 I/O 带宽 和 CPU 解码成本 之间的一场持久战。虽然跳过数据通常是好事,但跳过本身也有计算成本。arrow-rs 中 Parquet 读取器的目标是流水线式的延迟物化:首先评估谓词,然后访问投影列。对于过滤掉许多行的谓词,在评估之后再进行物化可以最大限度地减少读取和解码工作。
这种方法与 Abadi 等人的论文 列式 DBMS 中的物化策略 中的 LM-pipelined 策略非常相似:交错进行谓词评估和数据列访问,而不是一次性读取所有列并试图将它们重新拼接成行。
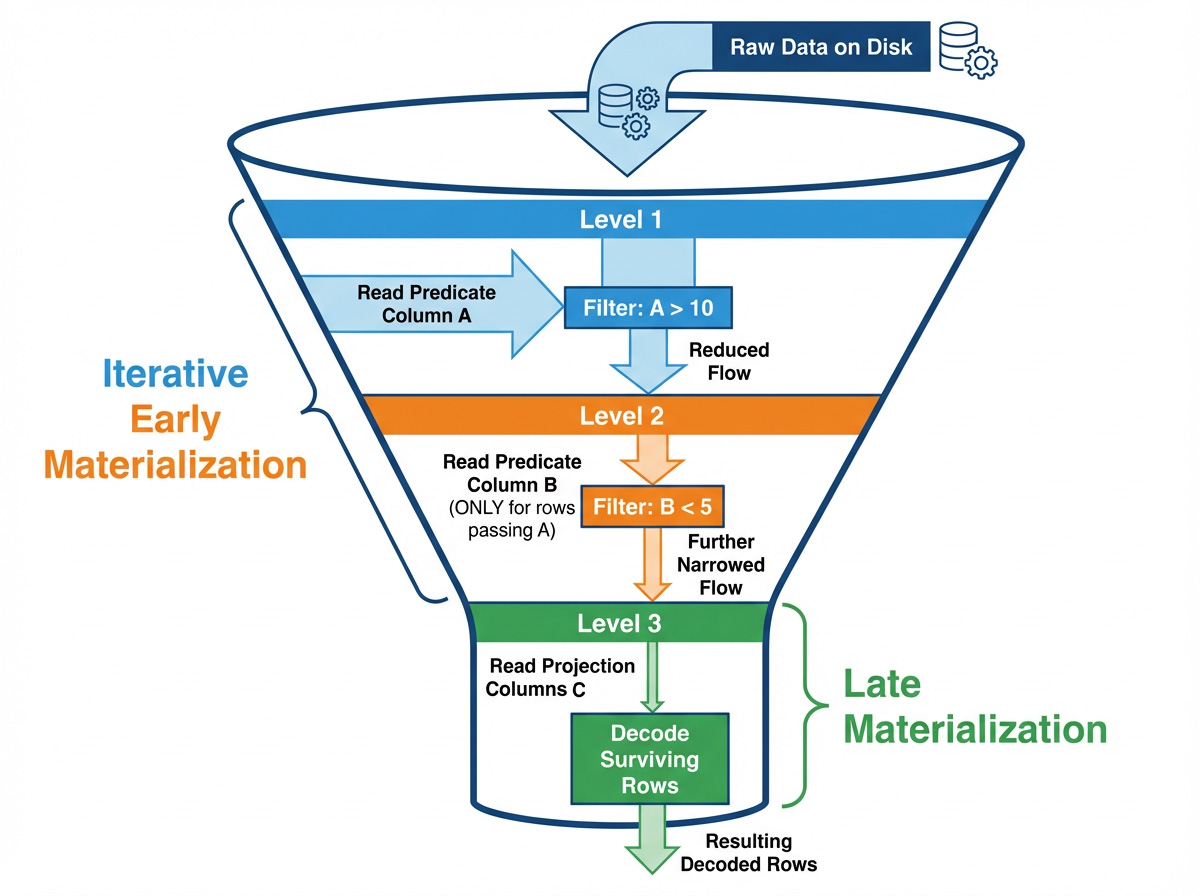
为了使用延迟物化评估像 SELECT B, C FROM table WHERE A > 10 AND B < 5 这样的查询,读取器遵循以下步骤:
- 读取列
A并评估A > 10以构建一个RowSelection(一个稀疏掩码),代表最初幸存的行集。 - 使用该
RowSelection读取列B中幸存的值,并评估B < 5,更新RowSelection使其更加稀疏。 - 使用细化后的
RowSelection读取列C(投影列),仅解码最终幸存的行。
本文的其余部分将详细介绍代码如何实现这一路径。
2. Rust Parquet 读取器中的延迟物化
2.1 LM-pipelined(流水线延迟物化)
“LM-pipelined”听起来像是教科书里的术语。在 arrow-rs 中,它简单地指一个按顺序运行的流水线:“读取谓词列 → 生成行选择 → 读取数据列”。这与并行策略形成对比,后者同时读取所有谓词列。虽然并行可以最大化多核 CPU 的利用率,但在列式存储中,流水线方法通常更优,因为每个过滤步骤都大幅减少了后续步骤需要读取和解析的数据量。
代码结构分为几个核心角色:
- ReadPlan / ReadPlanBuilder:将“读取哪些列以及使用什么行子集”编码为一个计划。它不会预先读取所有谓词列。它读取一列,收紧选择,然后继续。
-
RowSelection:有两种实现方式:用 游程编码(Run-length encoding) (RLE)(
RowSelector)来“跳过/选择 N 行”,或用 ArrowBooleanBuffer作为位掩码来过滤行。它是沿着流水线传递稀疏性的核心机制。 -
ArrayReader:负责解码。它接收一个
RowSelection并决定读取哪些页以及解码哪些值。
RowSelection 可以在 RLE 和位掩码之间动态切换。当间隙很小且稀疏度很高时,位掩码更快;RLE 则对大范围的页级跳过更友好。关于这种权衡的细节将在 3.1 节中介绍。
再次考虑查询:SELECT B, C FROM table WHERE A > 10 AND B < 5:
-
初始:
selection = None(相当于“全选”)。 -
读取 A:
ArrayReader分批解码列 A;谓词构建一个布尔掩码;RowSelection::from_filters将其转换为稀疏选择。 -
收紧:
ReadPlanBuilder::with_predicate通过RowSelection::and_then链接新的掩码。 -
读取 B:使用当前的
selection构建列 B 的读取器;读取器仅对选定的行执行 I/O 和解码,产生一个更稀疏的掩码。 -
合并:
selection = selection.and_then(selection_b);投影列现在只解码极小的行集。
代码位置和草图:
// Close to the flow in read_plan.rs (simplified)
let mut builder = ReadPlanBuilder::new(batch_size);
// 1) Inject external pruning (e.g., Page Index):
builder = builder.with_selection(page_index_selection);
// 2) Append predicates serially:
for predicate in predicates {
builder = builder.with_predicate(predicate); // internally uses RowSelection::and_then
}
// 3) Build readers; all ArrayReaders share the final selection strategy
let plan = builder.build();
let reader = ParquetRecordBatchReader::new(array_reader, plan);
我画了一个简单的流程图来说明这个流程,帮助你理解:
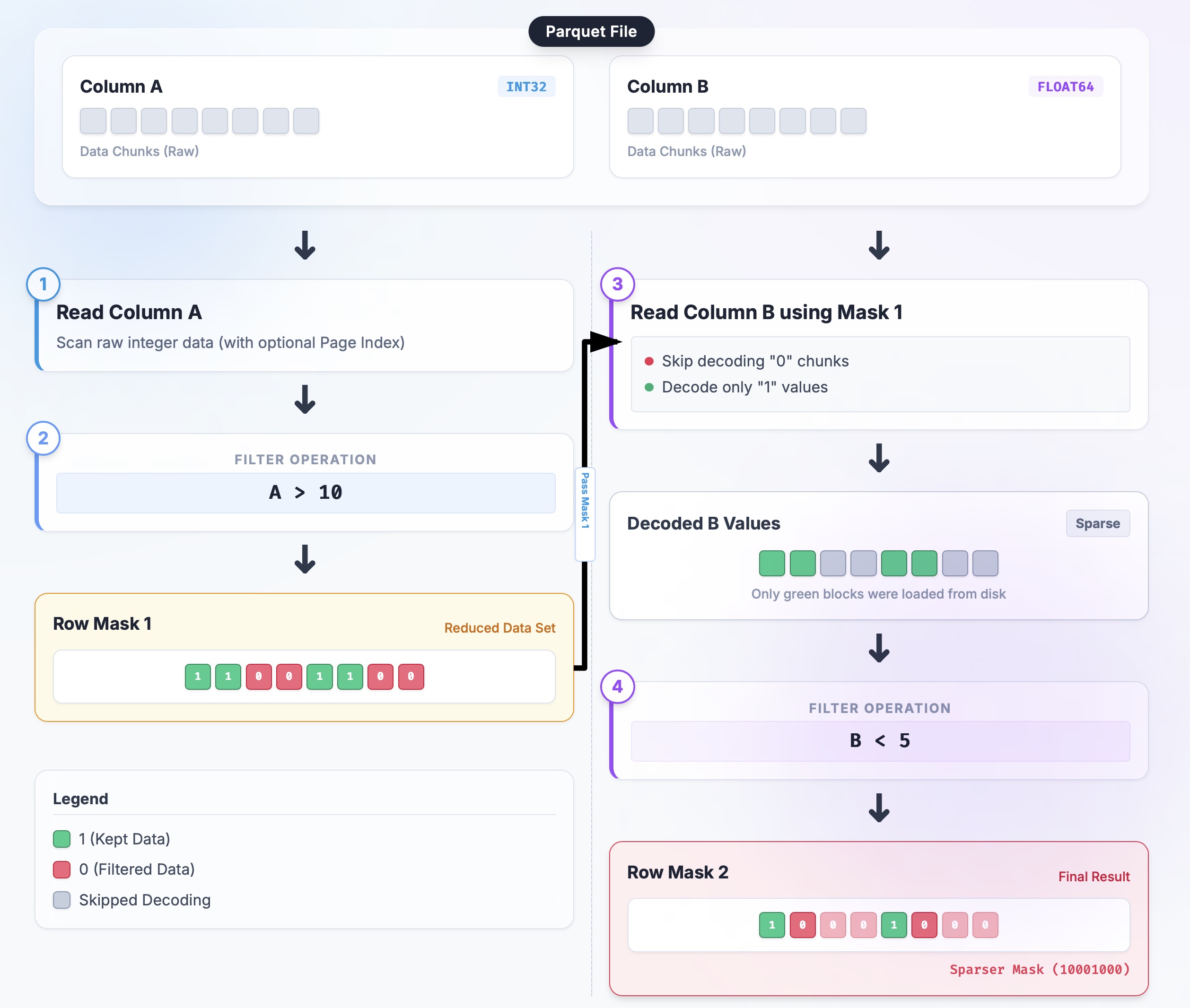
现在你已经了解了这个流水线是如何工作的,下一个问题是如何表示和组合这些稀疏选择(图中的 Row Mask),这就是 RowSelection 发挥作用的地方。
2.2 组合行选择器 (RowSelection::and_then)
RowSelection 代表了最终将生成的行集。它目前使用 RLE (RowSelector::select/skip(len)) 来描述稀疏范围。RowSelection::and_then 是“将一个选择应用于另一个”的核心操作:左侧参数是“已经通过的行”,右侧参数是“在通过的行中,哪些也通过了第二个过滤器”。输出是它们的布尔 AND。
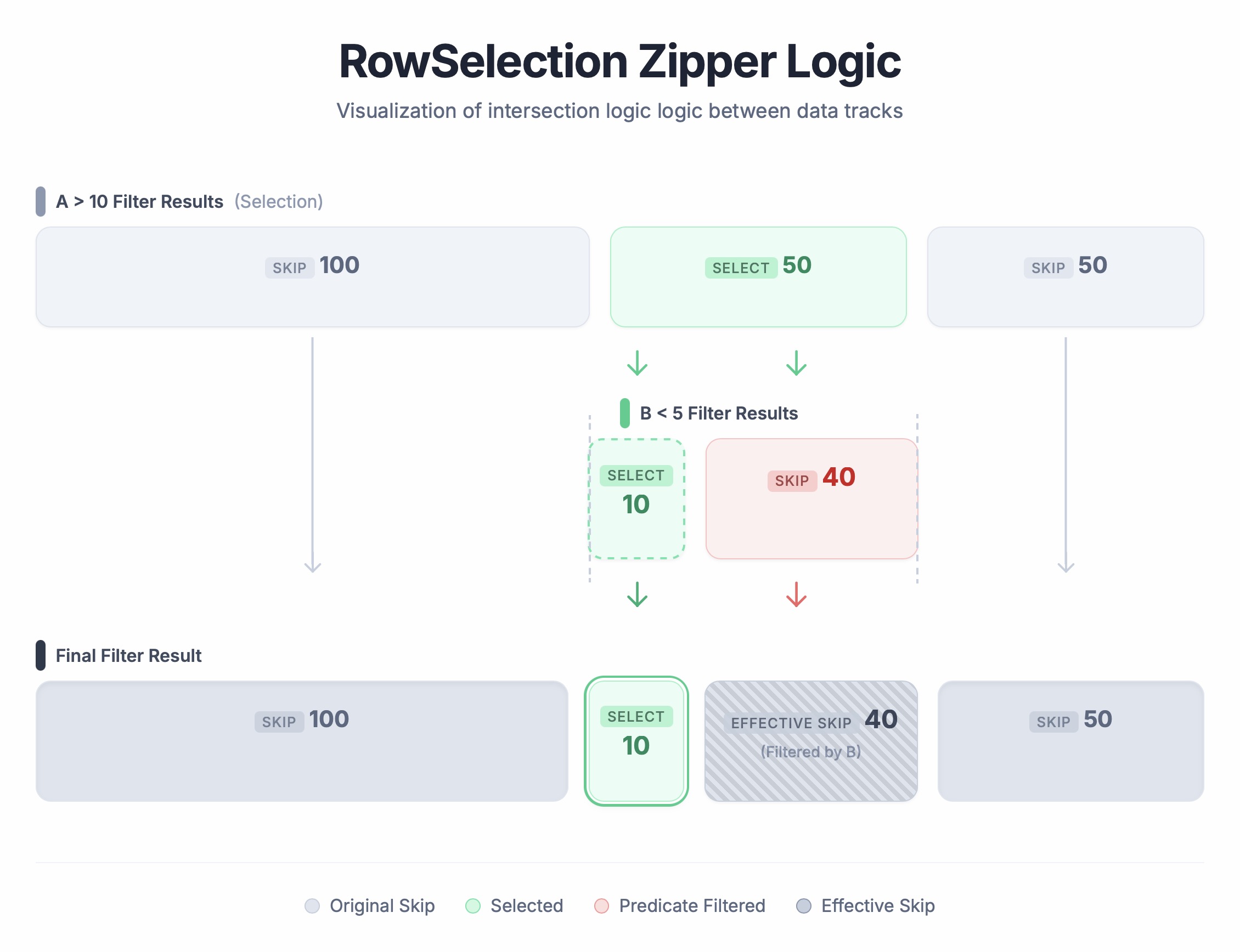
演练示例:
-
输入选择 A(已过滤):
[Skip 100, Select 50, Skip 50](物理行 100-150 被选中) -
选择 B(在 A 内部过滤):
[Select 10, Skip 40](在选中的 50 行中,只有前 10 行通过 B) -
结果:
[Skip 100, Select 10, Skip 90]。
运行过程: 想象一下它就像拉拉链:我们同时遍历两个列表,如下所示:
- 前 100 行:A 是 Skip → 结果是 Skip 100。
-
接下来的 50 行:A 是 Select。看 B:
- B 的前 10 个是 Select → 结果 Select 10。
- B 的剩余 40 个是 Skip → 结果 Skip 40。
- 最后 50 行:A 是 Skip → 结果 Skip 50。
结果:[Skip 100, Select 10, Skip 90]。
下面是代码示例:
// Example: Skip 100 rows, then take the next 10
let a: RowSelection = vec![RowSelector::skip(100), RowSelector::select(50)].into();
let b: RowSelection = vec![RowSelector::select(10), RowSelector::skip(40)].into();
let result = a.and_then(&b);
// Result should be: Skip 100, Select 10, Skip 40
assert_eq!(
Vec::<RowSelector>::from(result),
vec![RowSelector::skip(100), RowSelector::select(10), RowSelector::skip(40)]
);
这不断缩小过滤范围,同时只触及轻量级的元数据——没有数据拷贝。目前的 and_then 实现是一个双指针线性扫描;复杂度与选择器段数呈线性关系。谓词收缩选择的越多,后续的扫描就越便宜。
3. 工程挑战
延迟物化在理论上听起来很简单,但在像 arrow-rs 这样的生产级系统中实现它绝对是一场工程噩梦。历史上,这些技术非常棘手,一直被锁定在专有引擎中。在开源世界中,我们已经为此打磨了多年(看看 DataFusion 的这个 ticket 就知道了),终于,我们可以大展拳脚,与全物化一较高下。为了实现这一点,我们需要解决几个严重的工程挑战。
3.1 自适应 RowSelection 策略(位掩码 vs. RLE)
一个主要的障碍是为 RowSelection 选择正确的内部表示,因为最佳选择取决于稀疏模式。这篇论文 揭示了一个关键障碍:对于 RowSelection 来说,不存在“一刀切”的格式。研究人员发现,最佳的内部表示是一个移动的目标,随着数据的“密集”或“稀疏”程度——不断变化。
- 极度稀疏(例如,每 10,000 行 1 行):这里使用位掩码很浪费(每行 1 位加起来也不少),而 RLE 非常干净——只需几个选择器就搞定了。
- 稀疏但有微小间隙(例如,“读 1,跳 1”):RLE 会产生碎片化的混乱,让解码器超负荷工作;这里位掩码效率高得多。
由于两者各有优缺点,我们决定采用自适应策略来兼得两者之长(详情见 #arrow-rs/8733):
- 我们查看选择器的平均游程长度,并将其与阈值(目前为
32)进行比较。如果平均值太小,我们切换到位掩码;否则,我们坚持使用选择器(RLE)。 -
安全网:位掩码看起来很棒,直到遇到页修剪(Page Pruning),这可能会导致糟糕的“页丢失”恐慌(panic),因为掩码可能会盲目地试图过滤从未读取过的页中的行。
RowSelection逻辑会提防这种灾难配方,并强制切回 RLE 以防止崩溃(见 3.1.2)。
3.1.1 32 这个阈值是怎么来的?
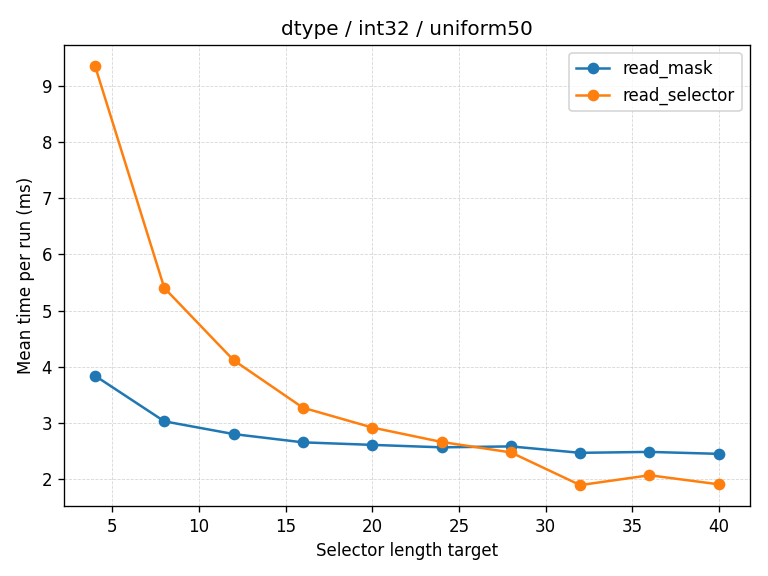
数字 32 并不是凭空捏造的。它来自于使用各种分布(均匀间隔、指数稀疏、随机噪声)进行的 数据驱动的“对决”。它在区分“破碎但密集”和“长跳跃区域”方面做得很好。未来,我们可能会基于数据类型采用更复杂的启发式方法。
下图展示了对决中的一个示例运行。蓝线是 read_selector (RLE),橙线是 read_mask (位掩码)。纵轴是时间(越低越好),横轴是平均游程长度。你可以看到性能曲线在 32 附近交叉。
3.1.2 位掩码陷阱:丢失的页
在实现自适应策略时,位掩码在纸面上看起来很完美,但在结合 页修剪(Page Pruning) 时隐藏着一个讨厌的陷阱。
在深入细节之前,先快速回顾一下页(更多内容见 3.2 节):Parquet 文件被切分成页(Page)。如果我们知道一个页在选择中没有行,我们根本不会触碰它——不解压,不解码。ArrayReader 甚至不知道它的存在。
案发现场:
想象一下读取一块数据[0,1,2,3,4,5,6],中间的四行 [1,2,3,4]被过滤掉了。碰巧其中两行 [2,3] 位于它们自己的页中,因此该页被完全修剪掉了。
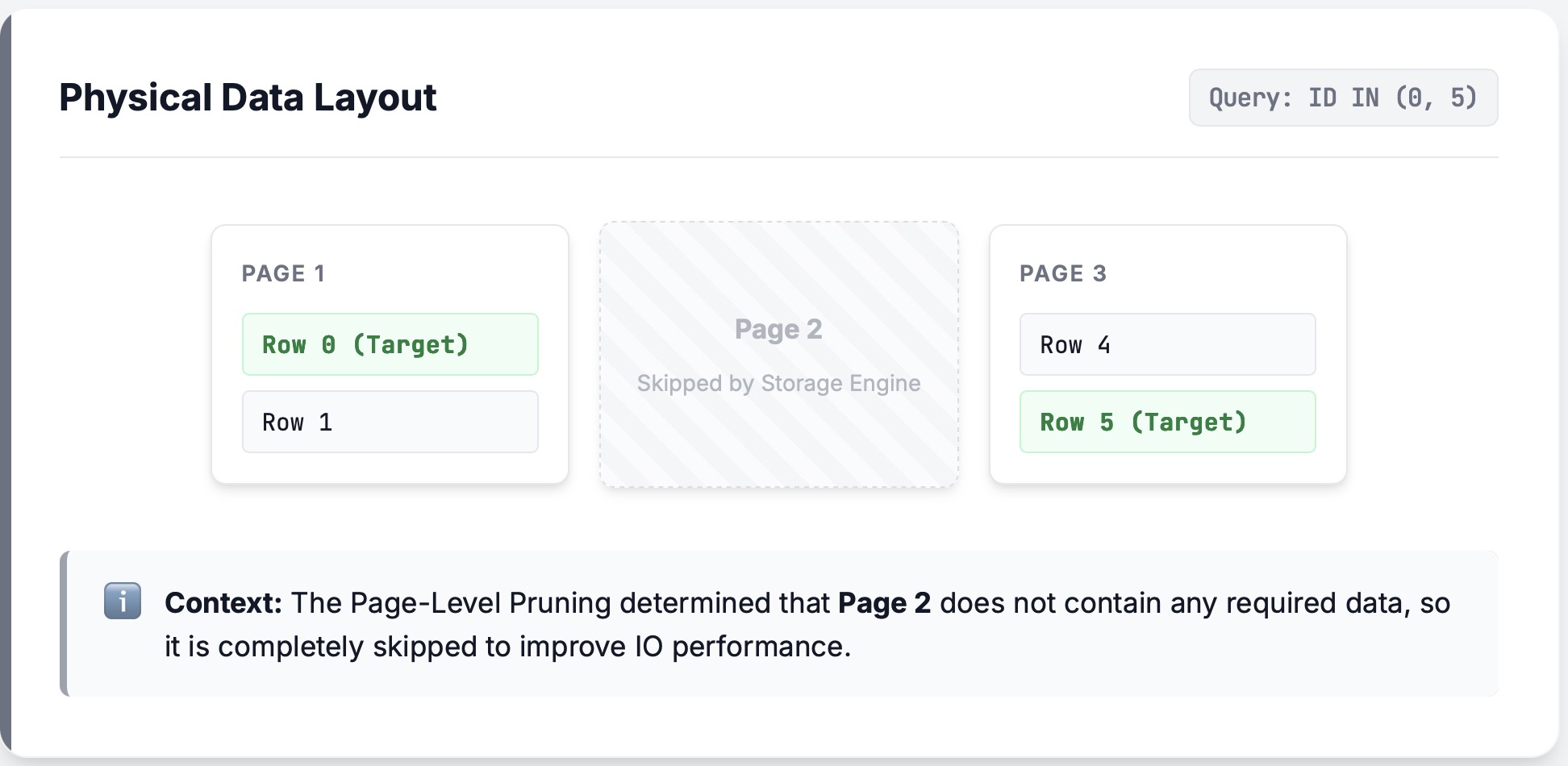
如果我们要使用 RLE (RowSelector),执行 Skip(4) 是一帆风顺的:我们只是跳过间隙。

问题:
然而,如果我们使用位掩码,读取器将首先解码所有 6 行,打算稍后过滤它们。但是中间的页不存在!一旦解码器遇到那个间隙,它就会恐慌(panic)。ArrayReader 是一个流处理单元——它不处理 I/O,因此不知道上层决定修剪页,所以它看不到前面的悬崖。
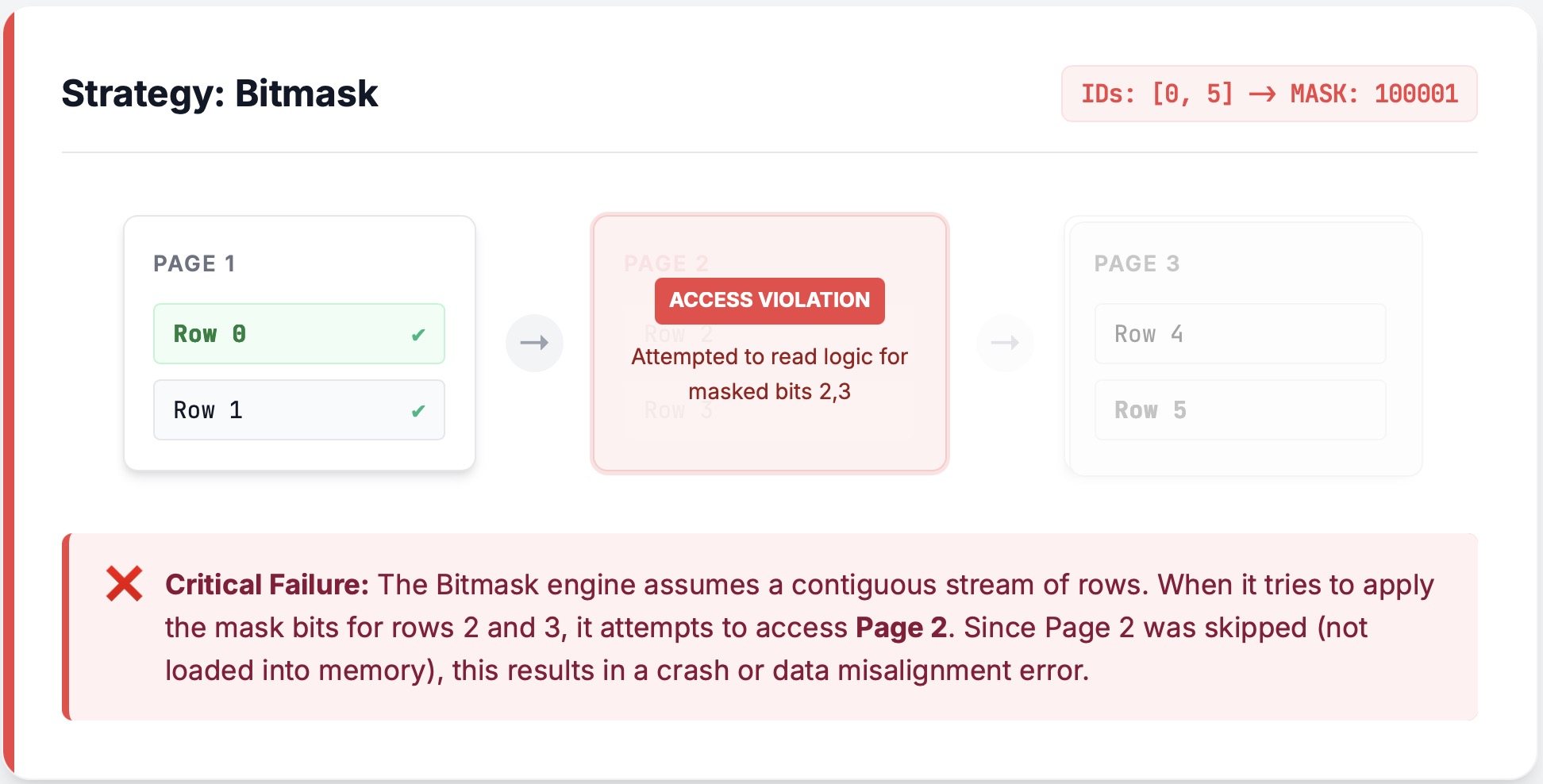
修复:
我们目前的解决方案既保守又稳健:如果我们检测到页修剪,我们就禁用位掩码并强制回退到 RLE。 在未来,我们希望扩展位掩码逻辑以使其感知页修剪(见 #arrow-rs/8845)。
// Auto prefers bitmask, but... wait, offset_index says page pruning is on.
let policy = RowSelectionPolicy::Auto { threshold: 32 };
let plan_builder = ReadPlanBuilder::new(1024).with_row_selection_policy(policy);
let plan_builder = override_selector_strategy_if_needed(
plan_builder,
&projection_mask,
Some(offset_index), // page index enables page pruning
);
// ...so we play it safe and switch to Selectors (RLE).
assert_eq!(plan_builder.row_selection_policy(), &RowSelectionPolicy::Selectors);
3.2 页修剪(Page Pruning)
终极的性能胜利是根本不进行 I/O 或解码。但是在现实世界中(特别是对象存储),发出一百万个微小的读取请求是性能杀手。arrow-rs 使用 Parquet PageIndex 来精确计算哪些页包含我们实际需要的数据。对于选择性极高的谓词,跳过页可以节省大量的 I/O,即使底层存储客户端合并了相邻的范围请求。另一个主要的胜利是减少了 CPU:我们完全跳过了对完全修剪页的解压和解码的繁重工作。
-
注意点:如果
RowSelection从一个页中哪怕只选择了一行,整个页也必须被解压。因此,这一步的效率很大程度上依赖于数据聚类和谓词之间的相关性。 -
实现:
RowSelection::scan_ranges使用每个页的元数据(first_row_index和compressed_page_size)进行计算,找出哪些范围是完全跳过的,仅返回所需的(offset, length)列表。
下面的代码示例说明了页跳过:
// Example: two pages; page0 covers 0..100, page1 covers 100..200
let locations = vec![
PageLocation { offset: 0, compressed_page_size: 10, first_row_index: 0 },
PageLocation { offset: 10, compressed_page_size: 10, first_row_index: 100 },
];
// RowSelection wants 150..160; page0 is total junk, only read page1
let sel: RowSelection = vec![
RowSelector::skip(150),
RowSelector::select(10),
RowSelector::skip(40),
].into();
let ranges = sel.scan_ranges(&locations);
assert_eq!(ranges.len(), 1); // Only request page1
下图说明了使用 RLE 选择进行的页跳过。第一页既不读取也不解码,因为没有行被选中。第二页被读取并完全解压(例如,zstd),然后只解码所需的行。第三页被完全解压和解码,因为所有行都被选中。
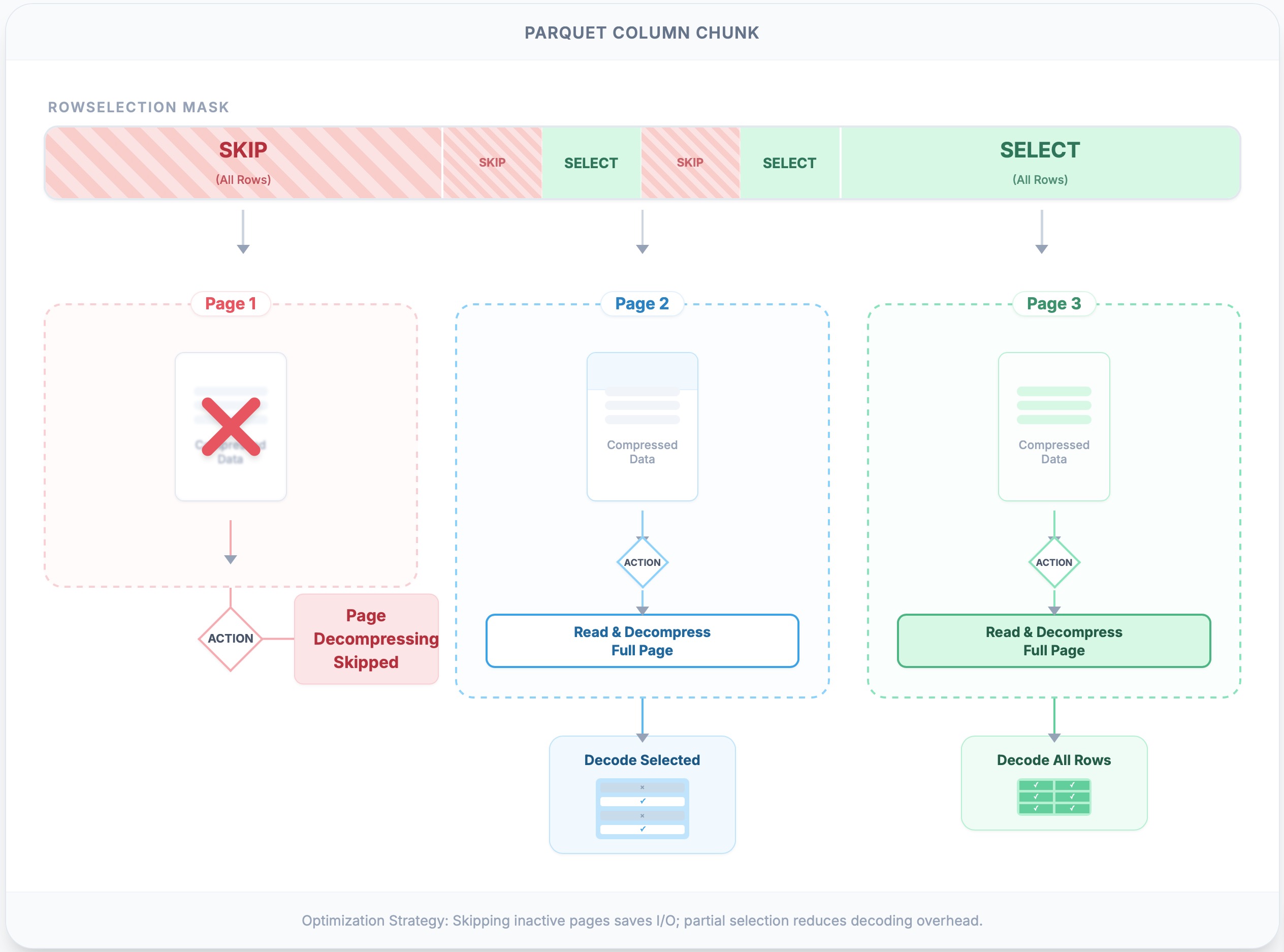
这种机制充当了逻辑行过滤和物理字节获取之间的桥梁。虽然我们无法将文件切分得比单个页更细(由于压缩边界),但页修剪确保了我们永远不会为页支付解压成本,除非它至少为结果贡献了一行。它达成了一种务实的平衡:利用粗粒度的页索引(Page Index)跳过大片数据,同时留给细粒度的 RowSelection 来处理幸存页内的具体行。
3.3 智能缓存
延迟物化引入了一个结构性的进退两难(原文是Catch-22,第二十二条军规):为了有效地跳过数据,我们必须先读取它。考虑像 SELECT A FROM table WHERE A > 10 这样的查询。读取器必须解码列 A 来评估过滤器。在传统的“读取所有内容”的方法中,这不是问题:列 A 只需留在内存中等待投影。然而,在严格的流水线中,“谓词”阶段和“投影”阶段是解耦的。一旦过滤器生成了 RowSelection,投影阶段发现它需要列 A,就会触发对同一数据的第二次读取。
如果不加干预,我们会支付“双重税”:一次解码用于决定保留什么,再一次解码用于实际保留它。在 #arrow-rs/7850 中引入的 CachedArrayReader 使用双层缓存架构解决了这个难题。它允许我们在第一次看到解码批次时(在过滤期间)将其存储起来,并稍后(在投影期间)重用。
但是为什么要两层?为什么不直接用一个大缓存?
- 共享缓存(乐观重用): 这是一个跨所有列和读取器共享的全局缓存。它有一个用户可配置的内存限制(容量)。当一个页因谓词被解码时,它被放置在这里。如果投影步骤紧接着运行,它可以“命中”这个缓存并避免 I/O。然而,因为内存是有限的,缓存驱逐随时可能发生。如果我们仅依赖于此,繁重的工作负载可能会在我们再次需要数据之前就将其驱逐。
- 本地缓存(确定性保证): 这是一个特定于单列读取器的私有缓存。它充当安全网。当一个列正在被主动读取时,数据被“钉”(Pin)在本地缓存中。这保证了数据在当前操作期间仍然可用,不受全局共享缓存驱逐的影响。
读取器在获取页时遵循严格的层级结构:
- 检查本地: 我已经钉住它了吗?
- 检查共享: 流水线的另一部分最近解码过它吗?如果是,将其提升到本地(钉住它)。
- 从源读取: 执行 I/O 和解码,然后插入到本地和共享缓存中。
这种双重策略让我们兼得两者之长:在过滤和投影步骤之间共享数据的效率,以及知道必要数据不会因内存压力而在查询中途消失的稳定性。
3.4 最小化拷贝和分配
arrow-rs 进行重大优化的另一个领域是避免不必要的拷贝。Rust 的 内存安全 设计使得拷贝变得容易,而每一次额外的分配和拷贝都会浪费 CPU 周期和内存带宽。一种幼稚的实现经常通过将数据解压到临时的 Vec 然后 memcpy 到 Arrow Buffer 而支付**“不必要的税”**。
对于定长类型(如整数或浮点数),这完全是多余的,因为它们的内存布局是相同的。PrimitiveArrayReader 通过 零拷贝转换 消除了这种开销:它不再拷贝字节,而是简单地将解码后的 Vec<T> 的所有权直接移交给底层的 Arrow Buffer。
3.5 对齐挑战
链式过滤是坐标系中的一种令人抓狂的练习。过滤器 N 中的“第 1 行”实际上可能是文件中的“第 10,001 行”,这是由于之前的过滤器所致。
-
我们如何保持正轨?:我们对每个
RowSelection操作(split_off,and_then,trim)进行 模糊测试 (fuzz test)。我们需要绝对确定相对偏移量和绝对偏移量之间的转换是精准无误的。这种正确性是保持读取器在批次边界、稀疏选择和页修剪这三重威胁下保持稳定的基石。
4. 结论
arrow-rs 中的 Parquet 读取器不仅仅是一个简单的文件读取器——它是一个伪装的微型查询引擎。我们融入了诸如谓词下推和延迟物化等高端特性。读取器只读取需要的内容,只解码必要的内容,在节省资源的同时保持正确性。以前,这些功能仅限于专有或紧密集成的系统。现在,感谢社区的努力,arrow-rs 将高级查询处理技术的好处带给了即使是轻量级的应用程序。
我们邀请您 加入社区,探索代码,进行实验,并为其不断的演进做出贡献。优化数据访问的旅程永无止境,我们可以一起推动开源数据处理可能性的边界。