3x-9x Faster Apache Parquet Footer Metadata Using a Custom Thrift Parser in Rust
Published
23 Oct 2025
By
Andrew Lamb (alamb)
Editor’s Note: While Apache Arrow and Apache Parquet are separate projects, the Arrow arrow-rs repository hosts the development of the parquet Rust crate, a widely used and high-performance Parquet implementation.
Summary
Version 57.0.0 of the parquet Rust crate decodes metadata more than three times faster than previous versions thanks to a new custom Apache Thrift parser. The new parser is both faster in all cases and enables further performance improvements not possible with generated parsers, such as skipping unnecessary fields and selective parsing.
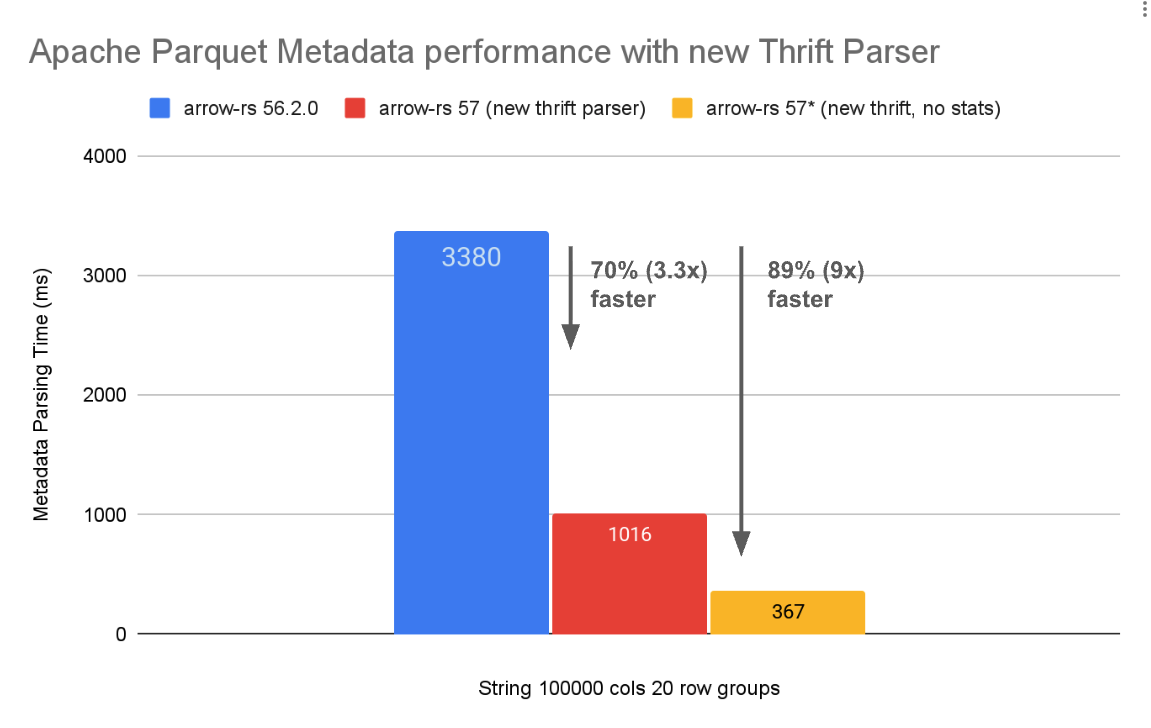
Figure 1: Performance comparison of Apache Parquet metadata parsing using a generated
Thrift parser (versions 56.2.0 and earlier) and the new
custom Thrift parser in arrow-rs version 57.0.0. No
changes are needed to the Parquet format itself.
See the benchmark page for more details.
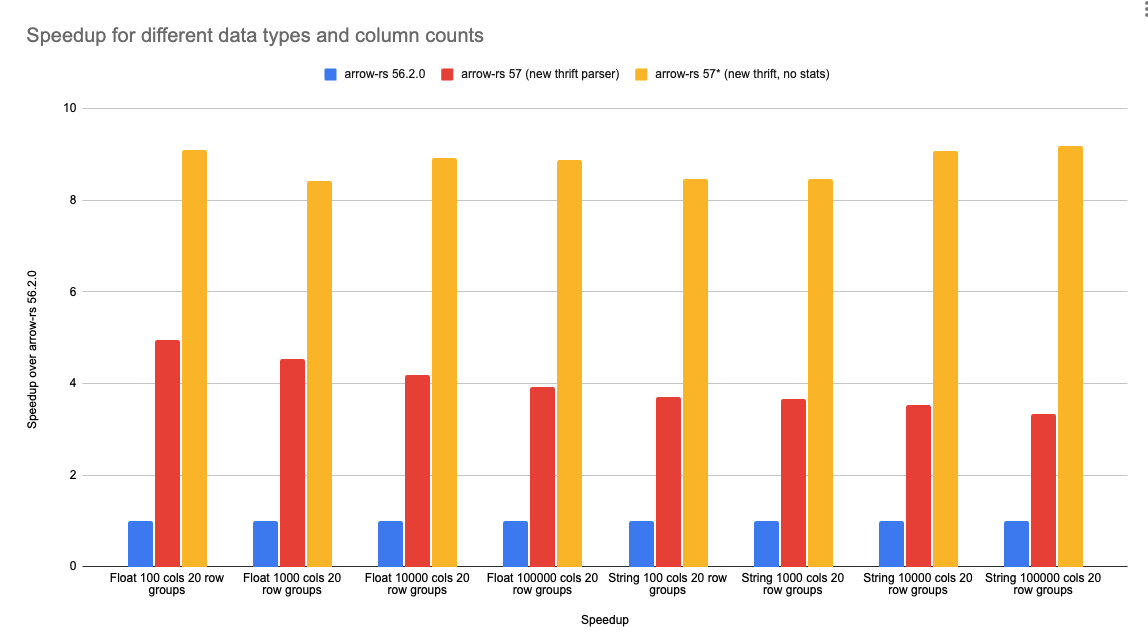
Figure 2: Speedup of the [custom Thrift decoder] for string and floating-point data types,
for 100, 1000, 10,000, and 100,000 columns. The new parser is faster in all cases,
and the speedup is similar regardless of the number of columns. See the benchmark page for more details.
Introduction: Parquet and the Importance of Metadata Parsing
Apache Parquet is a popular columnar storage format designed to be efficient for both storage and query processing. Parquet files consist of a series of data pages, and a footer, as shown in Figure 3. The footer contains metadata about the file, including schema, statistics, and other information needed to decode the data pages.
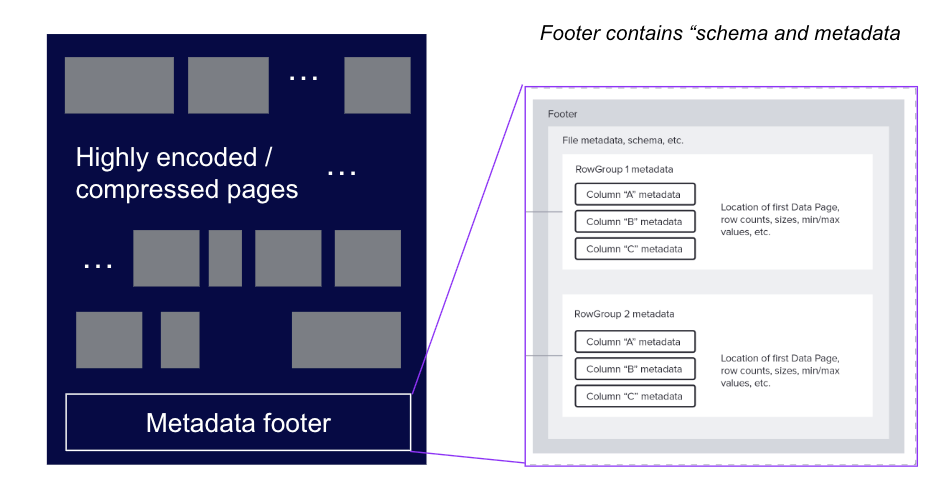
Figure 3: Structure of a Parquet file showing the header, data pages, and footer metadata.
Getting information stored in the footer is typically the first step in reading a Parquet file, as it is required to interpret the data pages. Parsing the footer is often performance critical:
- When reading from fast local storage, such as modern NVMe SSDs, footer parsing must be completed to know what data pages to read, placing it directly on the critical I/O path.
- Footer parsing scales linearly with the number of columns and row groups in a Parquet file and thus can be a bottleneck for tables with many columns or files with many row groups.
- Even in systems that cache the parsed footer in memory (see Using External Indexes, Metadata Stores, Catalogs and Caches to Accelerate Queries on Apache Parquet), the footer must still be parsed on cache miss.
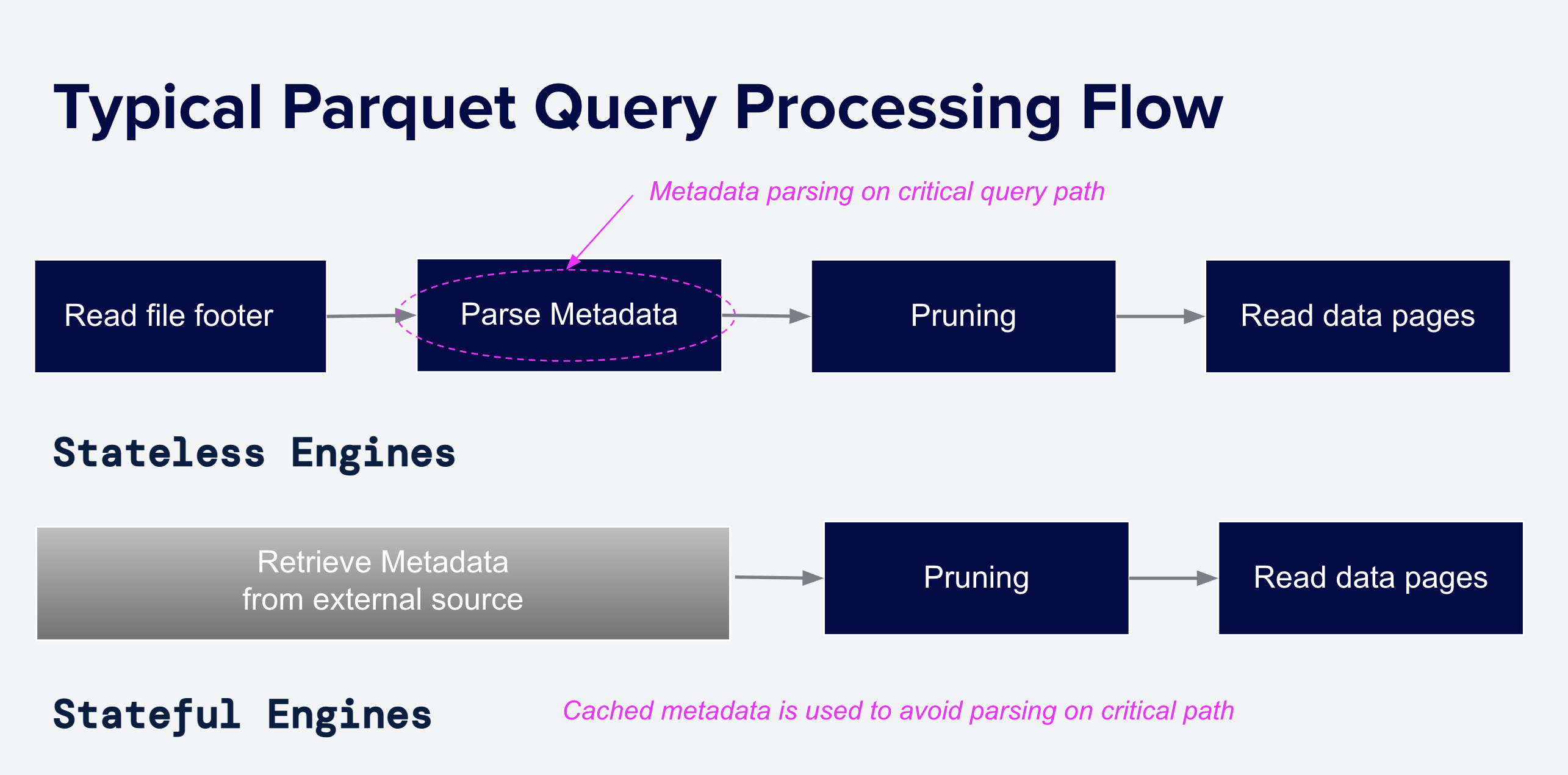
Figure 4: Typical processing flow for Parquet files for stateless and stateful systems. Stateless engines read the footer on every query, so the time taken to parse the footer directly adds to query latency. Stateful systems cache some or all of the parsed footer in advance of queries.
The speed of parsing metadata has grown even more important as Parquet spreads throughout the data ecosystem and is used for more latency-sensitive workloads such as observability, interactive analytics, and single-point lookups for Retrieval-Augmented Generation (RAG) applications feeding LLMs. As overall query times decrease, the proportion spent on footer parsing increases.
Background: Apache Thrift
Parquet stores metadata using Apache Thrift, a framework for network data types and service interfaces. It includes a data definition language similar to Protocol Buffers. Thrift definition files describe data types in a language-neutral way, and systems typically use code generators to automatically create code for a specific programming language to read and write those data types.
The parquet.thrift file defines the format of the metadata serialized at the end of each Parquet file in the Thrift Compact protocol, as shown below in Figure 5. The binary encoding is "variable-length", meaning that the length of each element depends on its content, not just its type. Smaller-valued primitive types are encoded in fewer bytes than larger values, and strings and lists are stored inline, prefixed with their length.
This encoding is space-efficient but, due to being variable-length, does not support random access: it is not possible to locate a particular field without scanning all previous fields. Other formats such as FlatBuffers provide random-access parsing and have been proposed as alternatives given their theoretical performance advantages. However, changing the Parquet format is a significant undertaking, requires buy-in from the community and ecosystem, and would likely take years to be adopted.
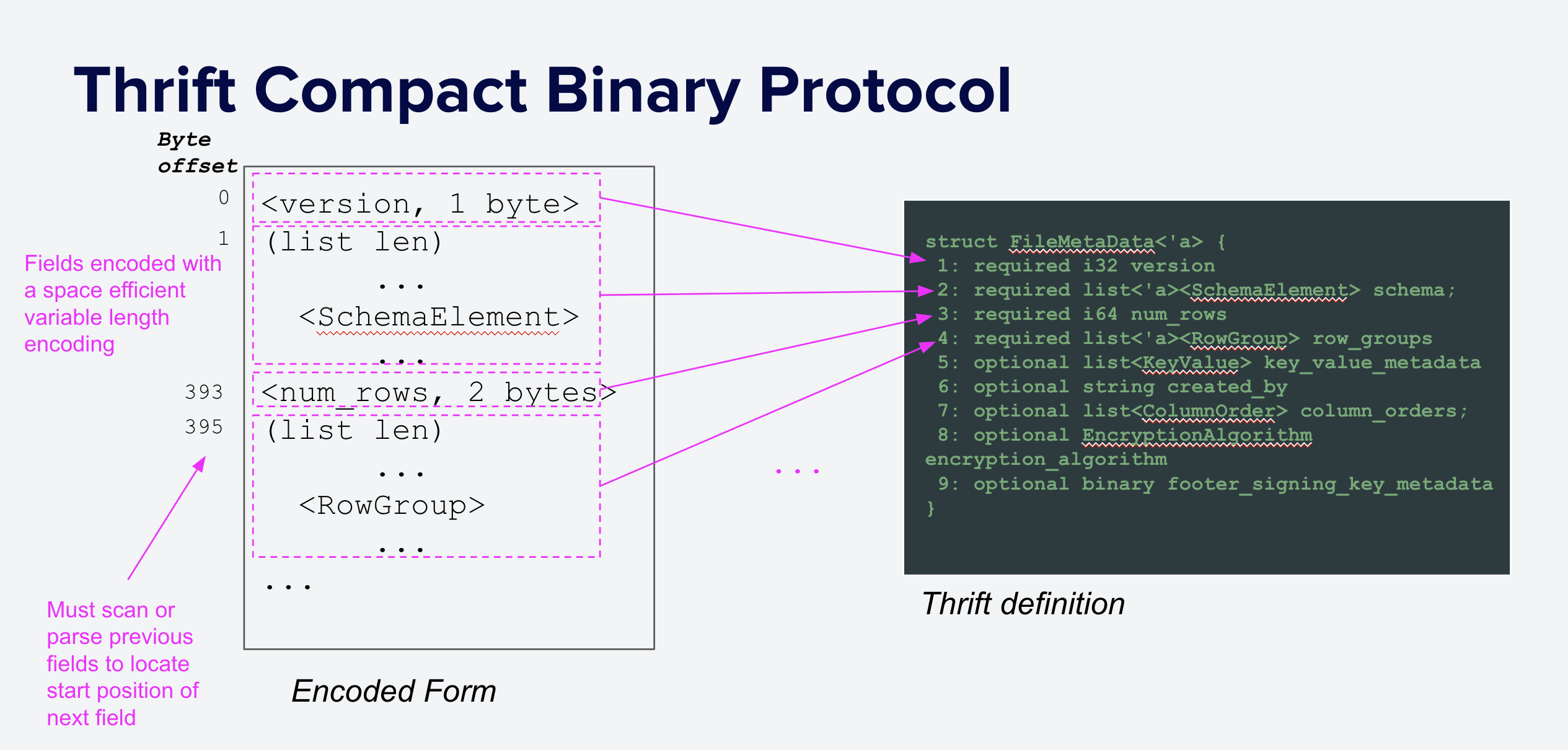
Figure 5: Parquet metadata is serialized using the Thrift Compact protocol. Each field is stored using a variable number of bytes that depends on its value. Primitive types use a variable-length encoding and strings and lists are prefixed with their lengths.
Despite Thrift's very real disadvantage due to lack of random access, software optimizations are much easier to deploy than format changes. Xiangpeng Hao's previous analysis theorized significant (2x–4x) potential performance improvements simply by optimizing the implementation of Parquet footer parsing (see How Good is Parquet for Wide Tables (Machine Learning Workloads) Really? for more details).
Processing Thrift Using Generated Parsers
Parsing Parquet metadata is the process of decoding the Thrift-encoded bytes into in-memory structures that can be used for computation. Most Parquet implementations use one of the existing Thrift compilers to generate a parser that converts Thrift binary data into generated code structures, and then copy relevant portions of those generated structures into API-level structures. For example, the C/C++ Parquet implementation includes a two-step process, as does parquet-java. DuckDB also contains a Thrift compiler–generated parser.
In versions 56.2.0 and earlier, the Apache Arrow Rust implementation used the
same pattern. The format module contains a parser generated by the thrift
crate and the parquet.thrift definition. Parsing metadata involves:
- Invoke the generated parser on the Thrift binary data, producing
generated in-memory structures (e.g.,
struct FileMetaData), then - Copy the relevant fields into a more user-friendly representation,
ParquetMetadata.
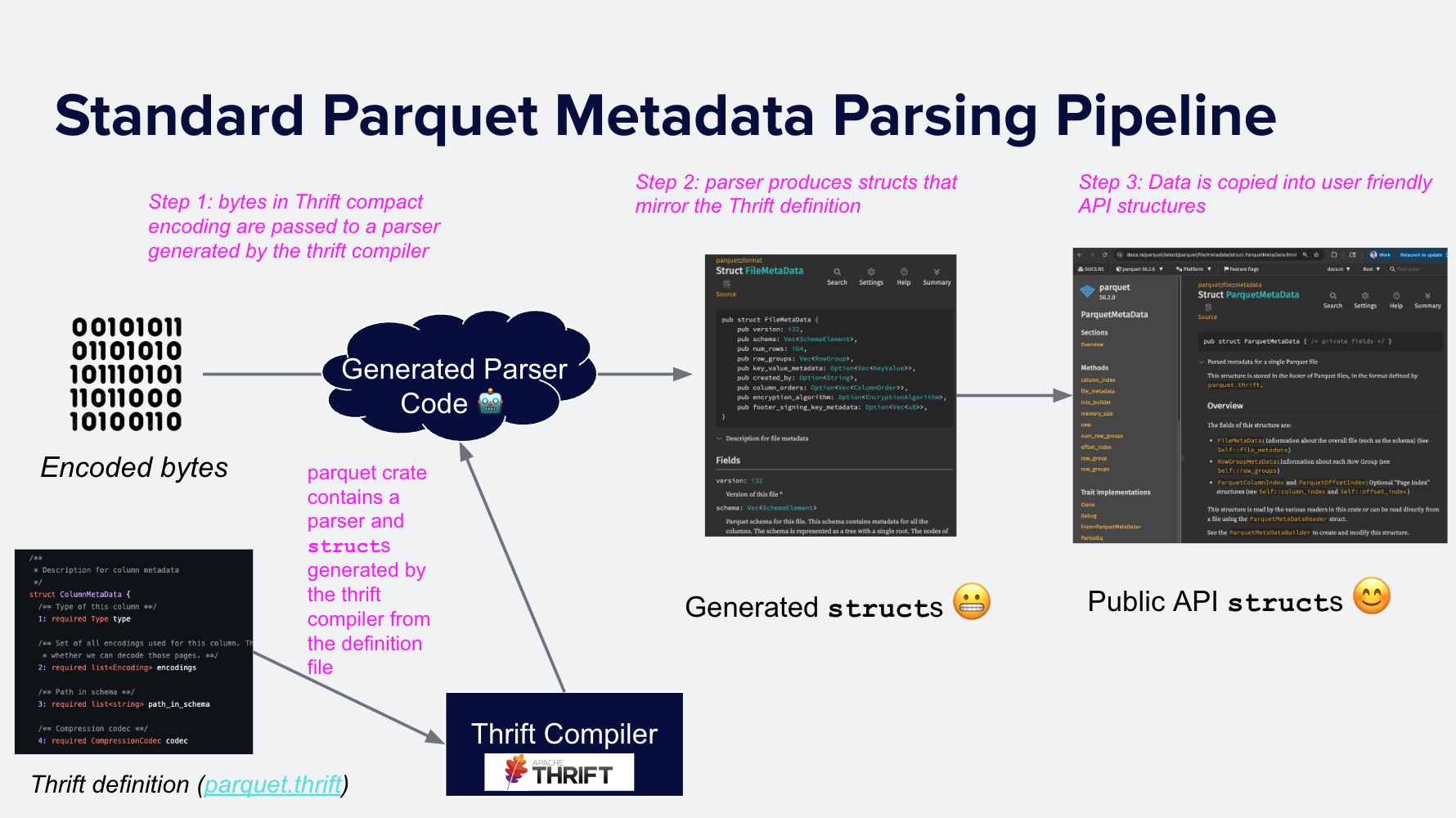
Figure 6: Two-step process to read Parquet metadata: A parser created with the
thrift crate and parquet.thrift parses the metadata bytes
into generated in-memory structures. These structures are then converted into
API objects.
The parsers generated by standard Thrift compilers typically parse all fields
in a single pass over the Thrift-encoded bytes, copying data into in-memory,
heap-allocated structures (e.g., Rust Vec, or C++ std::vector) as shown
in Figure 7 below.
Parsing all fields is straightforward and a good default choice given Thrift's original design goal of encoding network messages. Network messages typically don't contain extra information irrelevant for receivers; however, Parquet metadata often does contain information that is not needed for a particular query. In such cases, parsing the entire metadata into in-memory structures is wasteful.
For example, a query on a file with 1,000 columns that reads
only 10 columns and has a single column predicate
(e.g., time > now() - '1 minute') only needs
-
Statistics(orColumnIndex) for thetimecolumn -
ColumnChunkinformation for the 10 selected columns
The default strategy to parse (allocating and copying) all statistics and all
ColumnChunks results in creating 999 more statistics and 990 more ColumnChunks
than necessary. As discussed above, given the
variable encoding used for the metadata, all metadata bytes must still be
fetched and scanned; however, CPUs are (very) fast at scanning data, and
skipping parsing of unneeded fields speeds up overall metadata performance
significantly.

Figure 7: Generated Thrift parsers typically parse encoded bytes into structures requiring many small heap allocations, which are expensive.
New Design: Custom Thrift Parser
As is typical of generated code, opportunities for specializing the behavior of generated Thrift parsers is limited:
- It is not easy to modify (it is re-generated from the
Thrift definitions when they change and carries the warning
/* DO NOT EDIT UNLESS YOU ARE SURE THAT YOU KNOW WHAT YOU ARE DOING */). - It typically maps one-to-one with Thrift definitions, limiting additional optimizations such as zero-copy parsing, field skipping, and amortized memory allocation strategies.
- Its API is very stable (hard to change), which is important for easy maintenance when a large number
of projects are built using the thrift crate. For example, the
last release of the Rust
thriftcrate was almost three years ago at the time of this writing.
These limitations are a consequence of the Thrift project's design goals: general purpose code that is easy to embed in a wide variety of other projects, rather than any fundamental limitation of the Thrift format. Given our goal of fast Parquet metadata parsing, we needed a custom, easier to optimize parser, to convert Thrift binary directly into the needed structures (Figure 8). Since arrow-rs already did some postprocessing on the generated code and included a custom implementation of the compact protocol api, this change to a completely custom parser was a natural next step.

Figure 8: One-step Parquet metadata parsing using a custom Thrift parser. The Thrift binary is parsed directly into the desired in-memory representation with highly optimized code.
Our new custom parser is optimized for the specific subset of Thrift used by Parquet and contains various performance optimizations, such as careful memory allocation. The largest initial speedup came from removing intermediate structures and directly creating the needed in-memory representation. We also carefully hand-optimized several performance-critical code paths (see #8574, #8587, and #8599).
Maintainability
The largest concern with a custom parser is that it is more difficult to maintain than generated parsers because the custom parser must be updated to reflect any changes to parquet.thrift. This is a growing concern given the resurgent interest in Parquet and the recent addition of new features such as Geospatial and Variant types.
Thankfully, after discussions with the community, Jörn Horstmann developed
a Rust macro based approach for generating code with annotated Rust structs
that closely resemble the Thrift definitions while permitting additional hand
optimization where necessary. This approach is similar to the serde crate
where generic implementations can be generated with #[derive] annotations and
specialized serialization is written by hand where needed. Ed Seidl then
rewrote the metadata parsing code in the parquet crate using these macros.
Please see the final PR for details of the level of effort involved.
For example, here is the original Thrift definition of the FileMetaData structure (comments omitted for brevity):
struct FileMetaData {
1: required i32 version
2: required list<SchemaElement> schema;
3: required i64 num_rows
4: required list<RowGroup> row_groups
5: optional list<KeyValue> key_value_metadata
6: optional string created_by
7: optional list<ColumnOrder> column_orders;
8: optional EncryptionAlgorithm encryption_algorithm
9: optional binary footer_signing_key_metadata
}
And here (source) is the corresponding Rust structure using the Thrift macros (before Ed wrote a custom version in #8574):
thrift_struct!(
struct FileMetaData<'a> {
1: required i32 version
2: required list<'a><SchemaElement> schema;
3: required i64 num_rows
4: required list<'a><RowGroup> row_groups
5: optional list<KeyValue> key_value_metadata
6: optional string<'a> created_by
7: optional list<ColumnOrder> column_orders;
8: optional EncryptionAlgorithm encryption_algorithm
9: optional binary<'a> footer_signing_key_metadata
}
);
This system makes it easy to see the correspondence between the Thrift
definition and the Rust structure, and it is straightforward to support newly added
features such as GeospatialStatistics. The carefully hand-
optimized parsers for the most performance-critical structures, such as
RowGroupMetaData and ColumnChunkMetaData, are harder—though still
straightforward—to update (see #8587). However, those structures are also less
likely to change frequently.
Future Improvements
With the custom parser in place, we are working on additional improvements:
- Implementing special "skip" indexes to skip directly to the parts of the metadata that are needed for a particular query, such as the row group offsets.
- Selectively decoding only the statistics for columns that are needed for a particular query.
- Potentially contributing the macros back to the thrift crate.
Conclusion
We believe metadata parsing in many open source Parquet readers is slow primarily because they use parsers automatically generated by Thrift compilers, which are not optimized for Parquet metadata parsing. By writing a custom parser, we significantly sped up metadata parsing in the parquet Rust crate, which is widely used in the Apache Arrow ecosystem.
While this is not the first open source custom Thrift parser for Parquet metadata (CUDF has had one for many years), we hope that our results will encourage additional Parquet implementations to consider similar optimizations. The approach and optimizations we describe in this post are likely applicable to Parquet implementations in other languages, such as C++ and Java.
Previously, efforts like this were only possible at well-financed commercial enterprises. On behalf of the arrow-rs and Parquet contributors, we are excited to share this technology with the community in the upcoming 57.0.0 release and invite you to come join us and help make it even better!