Fast Streaming Inserts in DuckDB with ADBC
Published
10 Mar 2025
By
Loïc Alleyne (loicalleyne)
 # TL;DR
# TL;DR
DuckDB is rapidly becoming an essential part of data practitioners' toolbox, finding use cases in data engineering, machine learning, and local analytics. In many cases DuckDB has been used to query and process data that has already been saved to storage (file-based or external database) by another process. Arrow Database Connectivity APIs enable high-throughput data processing using DuckDB as the engine.
How it started
The company I work for is the leading digital out-of-home marketing platform, including a programmatic ad tech stack. For several years, my technical operations team was making use of logs emitted by the real-time programmatic auction system in the Apache Avro format. Over time we've built an entire operations and analytics back end using this data. Avro files are row-based which is less than ideal for analytics at scale, in fact it's downright painful. So much so that I developed and contributed an Avro reader feature to the Apache Arrow Go library to be able to convert Avro files to parquet. This data pipeline is now humming along transforming hundreds of GB/day from Avro to Parquet.
Since "any problem in computer science can be solved with another layer of indirection", the original system has grown layers (like an onion) and started to emit other logs, this time in Apache Parquet format...

- the new onion-layer (ahem...system component) sends Protobuf encoded messages to Kafka topics
- a Kafka Connect cluster with the S3 sink connector consumes topics and saves the parquet files to object storage
Due to the firehose of data, the cluster size over time grew to > 25 nodes and was producing thousands of small Parquet files (13 MB or smaller) an hour. This led to ever-increasing query latency, in some cases breaking our tools due to query timeouts (aka the small files problem). Not to mention that running aggregations on the raw data in our data warehouse wasn't fast or cheap.
DuckDB to the rescue... I think
I'd used DuckDB to process and analyse Parquet data so I knew it could do that very quickly. Then I came across this post on LinkedIn (Real-Time Analytics using Kafka and DuckDB), where someone has built a system for near-realtime analytics in Go using DuckDB.
The slides listed DuckDB's limitations:
The poster's solution batches data at the application layer managing to scale up ingestion 100x to ~20k inserts/second, noting that they thought that using the DuckDB Appender API could possibly increase this 10x. So, potentially ~200k inserts/second. Yayyyyy...
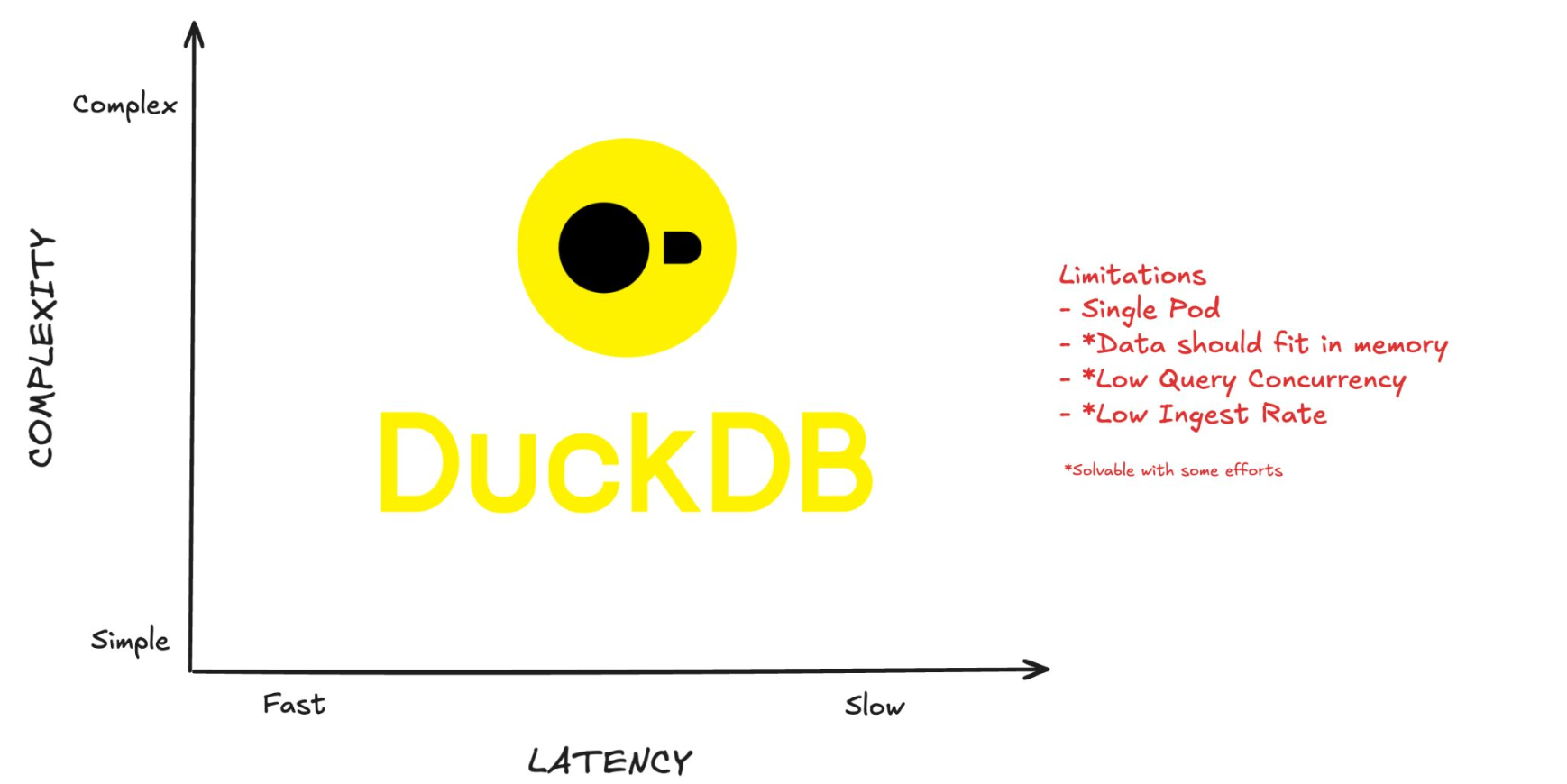 The poster's solution batches data at the application layer managing to scale up ingestion 100x to ~20k inserts/second, noting that they thought that using the DuckDB Appender API could possibly increase this 10x. So, potentially ~200k inserts/second. Yayyyyy...
The poster's solution batches data at the application layer managing to scale up ingestion 100x to ~20k inserts/second, noting that they thought that using the DuckDB Appender API could possibly increase this 10x. So, potentially ~200k inserts/second. Yayyyyy...
Then I noticed the data schema in the slides was flat and had only 4 fields (vs. OpenRTB schema with deeply nested Lists and Structs); and then looked at our monitoring dashboards whereupon I realized that at peak our system was emitting >250k events/second. [cue sad trombone]
Undeterred (and not particularly enamored with the idea of setting up/running/maintaining a Spark cluster), I suspected that Apache Arrow's columnar memory representation might still make DuckDB viable since it has an Arrow API; getting Parquet files would be as easy as running COPY...TO (format parquet).
Using a pattern found in a Github issue, I wrote a POC using github.com/marcboeker/go-duckdb to connect to a DB, retrieve an Arrow, create an Arrow Reader, register a view on the reader, then run an INSERT statement from the view.
This felt a bit like a rabbit pulling itself out of a hat, but no matter, it managed between ~74k and ~110k rows/sec on my laptop.
To make sure this was really the right solution, I also tried out DuckDB's Appender API (at time of writing the official recommendation for fast inserts) and managed... ~63k rows/sec on my laptop. OK, but... meh.
A new hope
In a discussion on the Gopher Slack, Matthew Topol aka zeroshade suggested using ADBC with its much simpler API. Who is Matt Topol you ask? Just the guy who literally wrote the book on Apache Arrow, that's who (In-Memory Analytics with Apache Arrow: Accelerate data analytics for efficient processing of flat and hierarchical data structures 2nd Edition). It's an excellent resource and guide for working with Arrow.
BTW, should you prefer an acronym to remember the name of the book, it's IMAAA:ADAFEPOFAHDS2E.
But I digress. Matt is also a member of the Apache Arrow PMC, a major contributor to the Go implementation of Apache Iceberg and generally a nice, helpful guy.

ADBC
ADBC is:
-
A set of abstract APIs in different languages (C/C++, Go, and Java, with more on the way) for working with databases and Arrow data.
For example, result sets of queries in ADBC are all returned as streams of Arrow data, not row-by-row.
-
A set of implementations of that API in different languages (C/C++, C#/.NET, Go, Java, Python, and Ruby) that target different databases (e.g. PostgreSQL, SQLite, DuckDB, any database supporting Flight SQL).
Going back to the drawing board, I created Quacfka, a Go library built using ADBC and split out my system into 3 worker pools, connected by channels:
- Kafka clients consuming topic messages and writing the bytes to a message channel
- Processing routines using the Bufarrow library to deserialize Protobuf data and append it to Arrow arrays, writing Arrow Records to a record channel
- DuckDB inserters binding the Arrow Records to ADBC statements and executing insertions
I first ran these in series to determine how fast each could run:
2025/01/23 23:39:27 kafka read start with 8 readers
2025/01/23 23:39:41 read 15728642 kafka records in 14.385530 secs @1093365.498477 messages/sec
2025/01/23 23:39:41 deserialize []byte to proto, convert to arrow records with 32 goroutines start
2025/01/23 23:40:04 deserialize to arrow done - 15728642 records in 22.283532 secs @ 705841.509812 messages/sec
2025/01/23 23:40:04 ADBC IngestCreateAppend start with 32 connections
2025/01/23 23:40:25 duck ADBC insert 15728642 records in 21.145649535 secs @ 743824.007783 rows/sec
With this architecture decided, I then started running the workers concurrently, instrumenting the system, profiling my code to identify performance issues and tweaking the settings to maximize throughput. It seemed to me that there was enough performance headroom to allow for in-flight aggregations.
One issue: Despite DuckDB's excellent lightweight compression, inserts from this source were making the file size increase at a rate of ~8GB/minute. Putting inserts on hold to export the Parquet files and release the storage would reduce the overall throughput to an unacceptable level. I decided to implement a rotation of database files based on a file size threshold.
DuckDB being able to query Hive partitioned parquet on disk or in object storage, the analytics part could be decoupled from the data ingestion pipeline by running a separate querying server pointing at wherever the parquet files would end up.
Iterating, I created several APIs to try to make in-flight aggregations efficient enough to keep the overall throughput above my 250k rows/second target.
The first two either ran into issues of data locality or weren't optimized enough:
- CustomArrows : functions to run on each Arrow Record to create a new Record to insert along with the original
- DuckRunner : run a series of queries on the database file before rotation
Reasoning that if unnesting deeply nested data in Arrow Record arrays was causing data locality issues:
- Normalizer: a Bufarrow API used in the in the deserialization function to normalize the message data and append it to another Arrow Record, inserted into a separate table
This approach allowed throughput to go back to levels almost as high as without Normalizer - flat data is much faster to process and insert.
Oh, we're halfway there...livin' on a prayer
Next, I tried opening concurrent connections to multiple databases. BAM! Segfault. DuckDB concurrency model isn't designed that way. From within a process only a single database (in-memory or file) can be opened, then other database files can be attached to the central db's catalog.
Having already decided to rotate DB files, I decided to make a separate program (Runner) to process the database files as they were rotated, running aggregations on normalized data and table dumps to parquet. This meant setting up an RPC connection between the two and figuring out a backpressure mechanism to avoid disk full events.
However having the two running simultaneously was causing memory pressure issues, not to mention massively slowing down the throughput. Upgrading the VM to one with more vCPUs and memory only helped a little, there was clearly some resource contention going on.
Since Go 1.5, the default GOMAXPROCS value is the number of CPU cores available. What if this was reduced to "sandbox" the ingestion process, along with setting the DuckDB thread count in the Runner? This actually worked so well, it increased the overall throughput. Runner runs the COPY...TO...parquet queries, walks the parquet output folder, uploads files to object storage and deletes the uploaded files. Balancing the DuckDB file rotation size threshold in Quafka-Service allows Runner to keep up and avoid a backlog of DB files on disk.
Results
Ingesting the raw data (14 fields with one deeply nested LIST.STRUCT.LIST field) + normalized data:
num_cpu: 60
runtime_os: linux
kafka_clients: 5
kafka_queue_cap: 983040
processor_routines: 32
arrow_queue_cap: 4
duckdb_threshold_mb: 4200
duckdb_connections: 24
normalizer_fields: 10
start_time: 2025-02-24T21:06:23Z
end_time: 2025-02-24T21:11:23Z
records: 123_686_901.00
norm_records: 122_212_452.00
data_transferred: 146.53 GB
duration: 4m59.585s
records_per_second: 398_271.90
total_rows_per_second: 806_210.41
transfer_rate: 500.86 MB/second
duckdb_files: 9
duckdb_files_MB: 38429
file_avg_duration: 33.579sHow many rows/second could we get if we only inserted the flat, normalized data? (Note: original records are still processed, just not inserted):
num_cpu: 60
runtime_os: linux
kafka_clients: 10
kafka_queue_cap: 1228800
processor_routines: 32
arrow_queue_cap: 4
duckdb_threshold_mb: 4200
duckdb_connections: 24
normalizer_fields: 10
start_time: 2025-02-25T19:04:33Z
end_time: 2025-02-25T19:09:36Z
records: 231_852_772.00
norm_records: 363_247_327.00
data_transferred: 285.76 GB
duration: 5m3.059s
records_per_second: 0.00
total_rows_per_second: 1_198_601.39
transfer_rate: 965.54 MB/second
duckdb_files: 5
duckdb_files_MB: 20056
file_avg_duration: 58.975s
Once deployed, the number of parquet files fell from ~3000 small files per hour to < 20 files per hour. Goodbye small files!

Challenges/Learnings
- DuckDB insertions are the bottleneck; network speed, Protobuf deserialization, building Arrow Records are not.
- For fastest insertion into DuckDB, Arrow Record Batches should contain at least 122880 rows (to align with DuckDB storage row group size).
- DuckDB won't let you open more than one database at once within the same process (results in a segfault). DuckDB is designed to run only once in a process, with a central database's catalog having the ability to add connections to other databases.
- Workarounds:
- Use separate processes for writing and reading multiple database files.
- Open a single DuckDB database and use ATTACH to attach other DB files.
- Workarounds:
- Flat data is much, much faster to insert than nested data.

ADBC provides DuckDB with a truly high-throughput data ingestion API, unlocking a slew of use cases for using DuckDB with streaming data, making this an ever more useful tool for data practitioners.