Announcing Apache Arrow DataFusion Comet
Published
06 Mar 2024
By
The Apache Arrow PMC (pmc)
Introduction
The Apache Arrow PMC is pleased to announce the donation of the Comet project, a native Spark SQL Accelerator built on Apache Arrow DataFusion.
Comet is an Apache Spark plugin that uses Apache Arrow DataFusion to accelerate Spark workloads. It is designed as a drop-in replacement for Spark's JVM based SQL execution engine and offers significant performance improvements for some workloads as shown below.
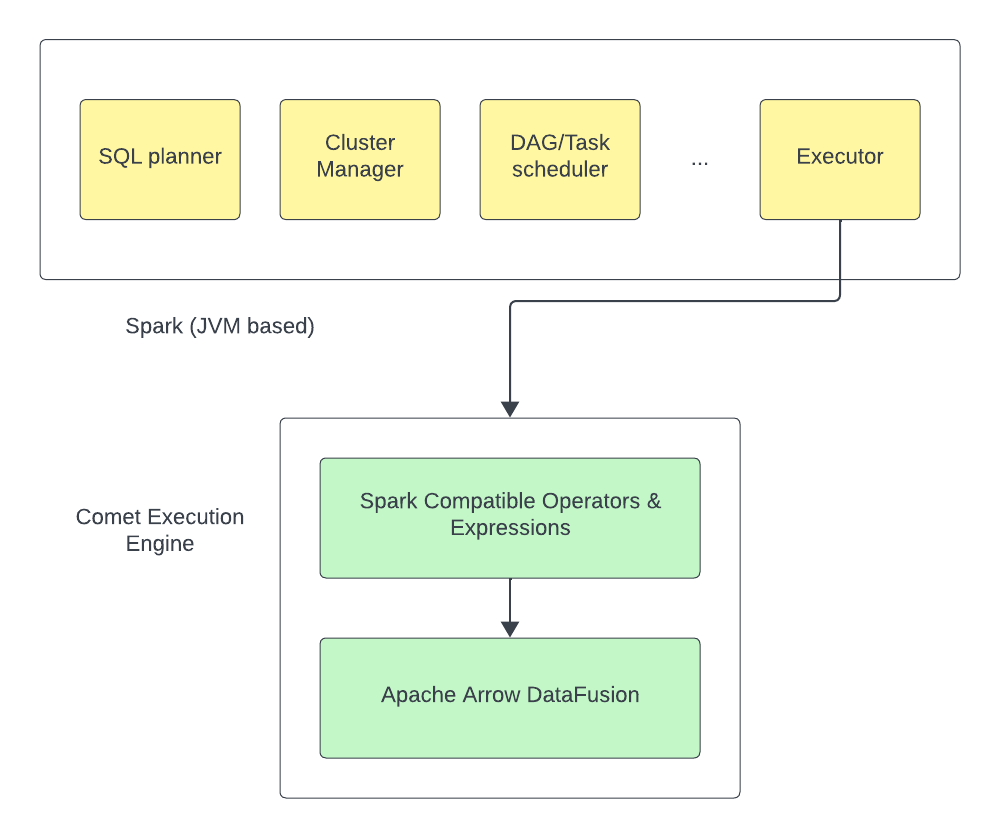
Comet is one of a growing class of projects that aim to accelerate Spark using native columnar engines such as the proprietary Databricks Photon Engine and open source projects Gluten, Spark RAPIDS, and Blaze (also built using DataFusion).
Comet was originally implemented at Apple and the engineers who worked on the project are also significant contributors to Arrow and DataFusion. Bringing Comet into the Apache Software Foundation will accelerate its development and grow its community of contributors and users.
Get Involved
Comet is still in the early stages of development and we would love to have you join us and help shape the project. We are working on an initial release, and expect to post another update with more details at that time.
Before then, here are some ways to get involved:
-
Learn more by visiting the Comet project page and reading the mailing list discussion about the initial donation.
-
Help us plan out the roadmap
-
Try out the project and provide feedback, file issues, and contribute code.