Skyhook: Bringing Computation to Storage with Apache Arrow
Published
31 Jan 2022
By
Jayjeet Chakraborty, Carlos Maltzahn, David Li, Tom Drabas
CPUs, memory, storage, and network bandwidth get better every year, but increasingly, they’re improving in different dimensions. Processors are faster, but their memory bandwidth hasn’t kept up; meanwhile, cloud computing has led to storage being separated from applications across a network link. This divergent evolution means we need to rethink where and when we perform computation to best make use of the resources available to us.
For example, when querying a dataset on a storage system like Ceph or Amazon S3, all the work of filtering data gets done by the client. Data has to be transferred over the network, and then the client has to spend precious CPU cycles decoding it, only to throw it away in the end due to a filter. While formats like Apache Parquet enable some optimizations, fundamentally, the responsibility is all on the client. Meanwhile, even though the storage system has its own compute capabilities, it’s relegated to just serving “dumb bytes”.
Thanks to the Center for Research in Open Source Software (CROSS) at the University of California, Santa Cruz, Apache Arrow 7.0.0 includes Skyhook, an Arrow Datasets extension that solves this problem by using the storage layer to reduce client resource utilization. We’ll examine the developments surrounding Skyhook as well as how Skyhook works.
Introducing Programmable Storage
Skyhook is an example of programmable storage: exposing higher-level functionality from storage systems for clients to build upon. This allows us to make better use of existing resources (both hardware and development effort) in such systems, reduces the implementation burden of common operations for each client, and enables such operations to scale with the storage layer.
Historically, big data systems like Apache Hadoop have tried to colocate computation and storage for efficiency. More recently, cloud and distributed computing have disaggregated computation and storage for flexibility and scalability, but at a performance cost. Programmable storage strikes a balance between these goals, allowing some operations to be run right next to the data while still keeping data and compute separate at a higher level.
In particular, Skyhook builds on Ceph, a distributed storage system that scales to exabytes of data while being reliable and flexible. With its Object Class SDK, Ceph enables programmable storage by allowing extensions that define new object types with custom functionality.
Skyhook Architecture
Let’s look at how Skyhook applies these ideas. Overall, the idea is simple: the client should be able to ask Ceph to perform basic operations like decoding files, filtering the data, and selecting columns. That way, the work gets done using existing storage cluster resources, which means it’s both adjacent to the data and can scale with the cluster size. Also, this reduces the data transferred over the network, and of course reduces the client workload.
On the storage system side, Skyhook uses the Ceph Object Class SDK to define scan operations on data stored in Parquet or Feather format. To implement these operations, Skyhook first implements a file system shim in Ceph’s object storage layer, then uses the existing filtering and projection capabilities of the Arrow Datasets library on top of that shim.
Then, Skyhook defines a custom “file format” in the Arrow Datasets layer. Queries against such files get translated to direct requests to Ceph using those new operations, bypassing the traditional POSIX file system layer. After decoding, filtering, and projecting, Ceph sends the Arrow record batches directly to the client, minimizing CPU overhead for encoding/decoding—another optimization Arrow makes possible. The record batches use Arrow’s compression support to further save bandwidth.
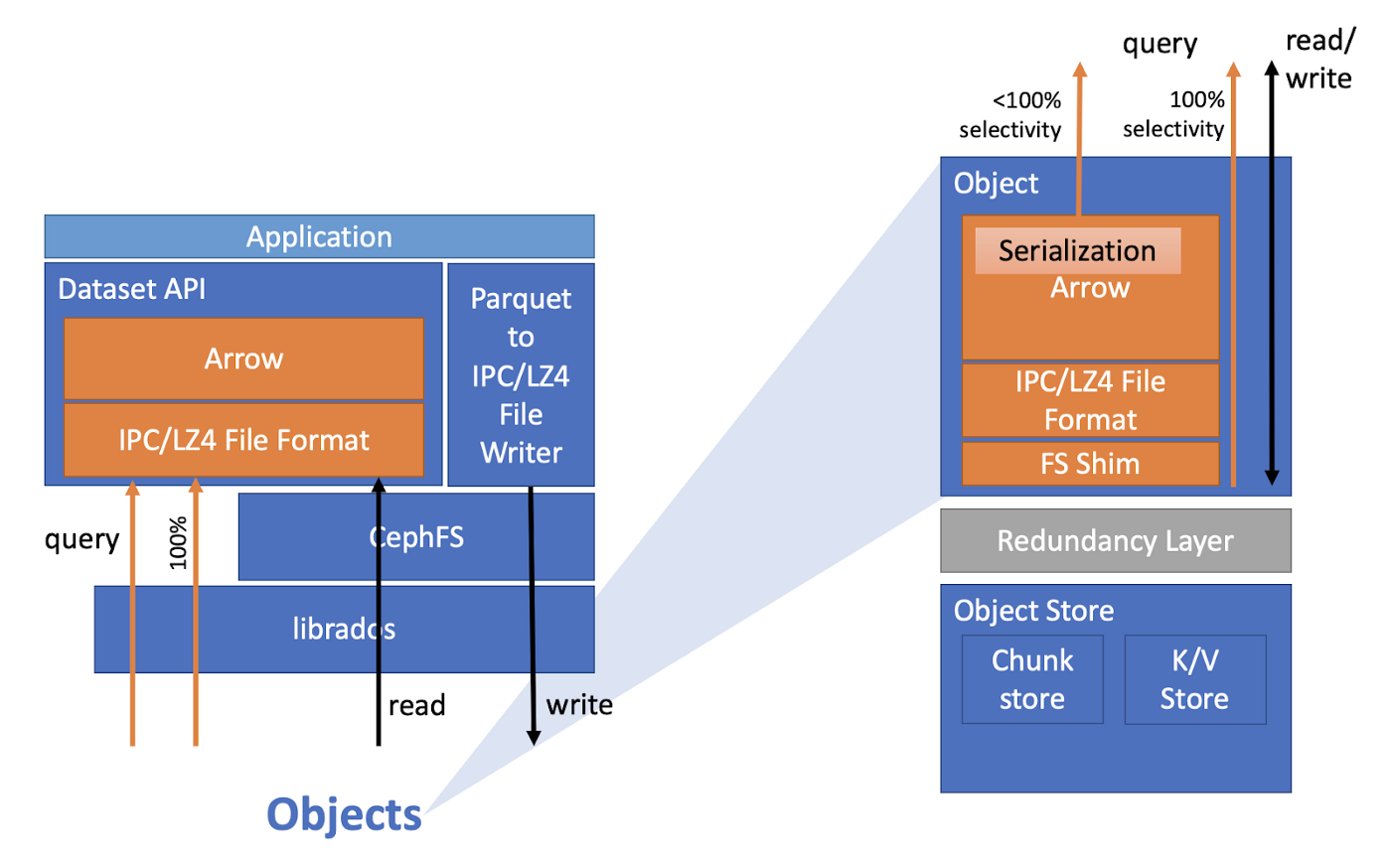
Skyhook also optimizes how Parquet files in particular are stored. Parquet files consist of a series of row groups, which each contain a chunk of the rows in a file. When storing such files, Skyhook either pads or splits them so that each row group is stored as its own Ceph object. By striping or splitting the file in this way, we can parallelize scanning at sub-file granularity across the Ceph nodes for further performance improvements.
Applications
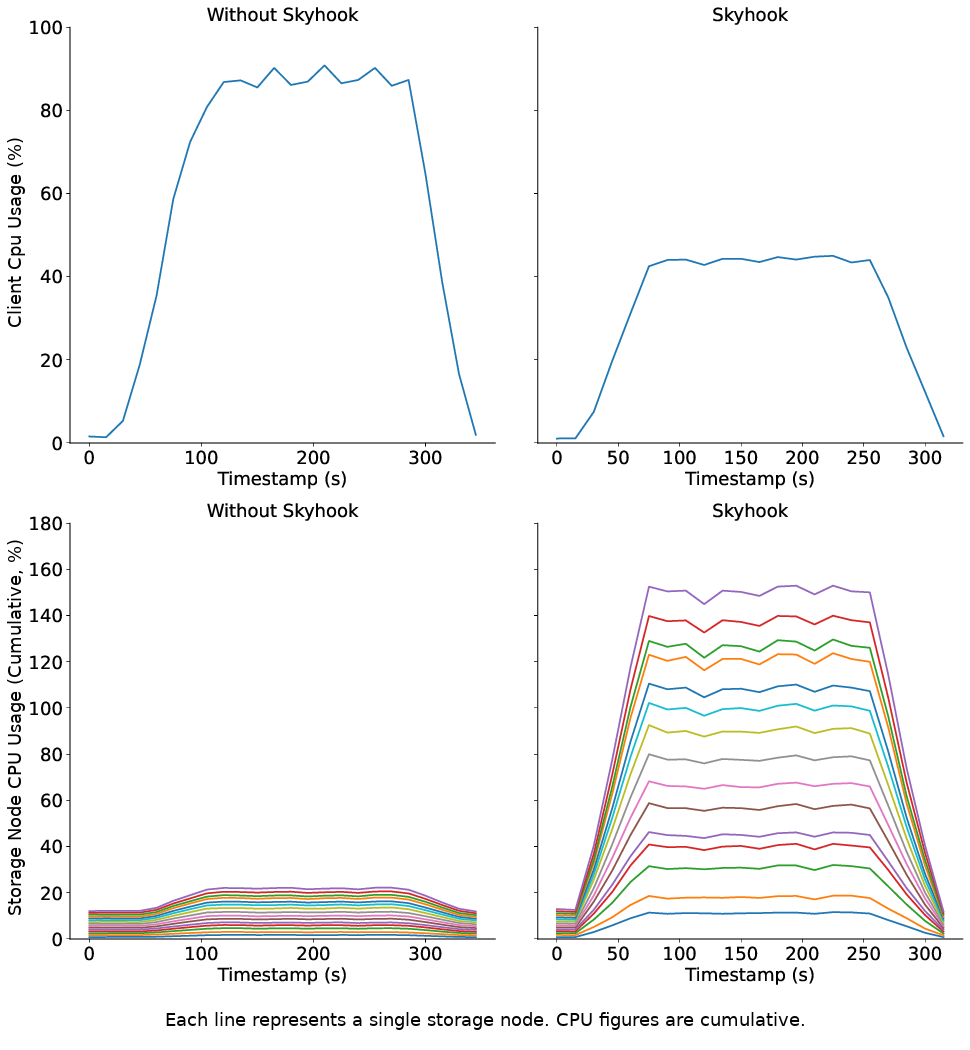
In benchmarks, Skyhook has minimal storage-side CPU overhead and virtually eliminates client-side CPU usage. Scaling the storage cluster decreases query latency commensurately. For systems like Dask that use the Arrow Datasets API, this means that just by switching to the Skyhook file format, we can speed up dataset scans, reduce the amount of data that needs to be transferred, and free up CPU resources for computations.
Of course, the ideas behind Skyhook apply to other systems adjacent to and beyond Apache Arrow. For example, “lakehouse” systems like Apache Iceberg and Delta Lake also build on distributed storage systems, and can naturally benefit from Skyhook to offload computation. Additionally, in-memory SQL-based query engines like DuckDB, which integrate seamlessly with Apache Arrow, can benefit from Skyhook by offloading portions of SQL queries.
Summary and Acknowledgements
Skyhook, available in Arrow 7.0.0, builds on research into programmable storage systems.
By pushing filters and projections to the storage layer, we can speed up dataset scans by freeing precious CPU resources on the client, reducing the amount of data sent across the network, and better utilizing the scalability of systems like Ceph.
To get started, just build Arrow with Skyhook enabled, deploy the Skyhook object class extensions to Ceph (see “Usage” in the announcement post), and then use the SkyhookFileFormat to construct an Arrow dataset.
A small code example is shown here.
// Licensed to the Apache Software Foundation (ASF) under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use this file except in compliance
// with the License. You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing,
// software distributed under the License is distributed on an
// "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
// KIND, either express or implied. See the License for the
// specific language governing permissions and limitations
// under the License.
#include <arrow/compute/api.h>
#include <arrow/dataset/api.h>
#include <arrow/filesystem/api.h>
#include <arrow/table.h>
#include <skyhook/client/file_skyhook.h>
#include <cstdlib>
#include <iostream>
#include <memory>
#include <string>
namespace cp = arrow::compute;
namespace ds = arrow::dataset;
namespace fs = arrow::fs;
// Demonstrate reading a dataset via Skyhook.
arrow::Status ScanDataset() {
// Configure SkyhookFileFormat to connect to our Ceph cluster.
std::string ceph_config_path = "/etc/ceph/ceph.conf";
std::string ceph_data_pool = "cephfs_data";
std::string ceph_user_name = "client.admin";
std::string ceph_cluster_name = "ceph";
std::string ceph_cls_name = "skyhook";
std::shared_ptr<skyhook::RadosConnCtx> rados_ctx =
std::make_shared<skyhook::RadosConnCtx>(ceph_config_path, ceph_data_pool,
ceph_user_name, ceph_cluster_name,
ceph_cls_name);
ARROW_ASSIGN_OR_RAISE(auto format,
skyhook::SkyhookFileFormat::Make(rados_ctx, "parquet"));
// Create the filesystem.
std::string root;
ARROW_ASSIGN_OR_RAISE(auto fs, fs::FileSystemFromUri("file:///mnt/cephfs/nyc", &root));
// Create our dataset.
fs::FileSelector selector;
selector.base_dir = root;
selector.recursive = true;
ds::FileSystemFactoryOptions options;
options.partitioning = std::make_shared<ds::HivePartitioning>(
arrow::schema({arrow::field("payment_type", arrow::int32()),
arrow::field("VendorID", arrow::int32())}));
ARROW_ASSIGN_OR_RAISE(auto factory,
ds::FileSystemDatasetFactory::Make(fs, std::move(selector),
std::move(format), options));
ds::InspectOptions inspect_options;
ds::FinishOptions finish_options;
ARROW_ASSIGN_OR_RAISE(auto schema, factory->Inspect(inspect_options));
ARROW_ASSIGN_OR_RAISE(auto dataset, factory->Finish(finish_options));
// Scan the dataset.
auto filter = cp::greater(cp::field_ref("payment_type"), cp::literal(2));
ARROW_ASSIGN_OR_RAISE(auto scanner_builder, dataset->NewScan());
ARROW_RETURN_NOT_OK(scanner_builder->Filter(filter));
ARROW_RETURN_NOT_OK(scanner_builder->UseThreads(true));
ARROW_ASSIGN_OR_RAISE(auto scanner, scanner_builder->Finish());
ARROW_ASSIGN_OR_RAISE(auto table, scanner->ToTable());
std::cout << "Got " << table->num_rows() << " rows" << std::endl;
return arrow::Status::OK();
}
int main(int, char**) {
auto status = ScanDataset();
if (!status.ok()) {
std::cerr << status.message() << std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}
We would like to acknowledge Ivo Jimenez, Jeff LeFevre, Michael Sevilla, and Noah Watkins for their contributions to this project.
This work was supported in part by the National Science Foundation under Cooperative Agreement OAC-1836650, the US Department of Energy ASCR DE-NA0003525 (FWP 20-023266), and the Center for Research in Open Source Software (cross.ucsc.edu).
For more information, see these papers and articles:
- SkyhookDM: Data Processing in Ceph with Programmable Storage. (USENIX ;login: issue Summer 2020, Vol. 45, No. 2)
- SkyhookDM is now a part of Apache Arrow! (Medium)
- Towards an Arrow-native Storage System. (arXiv.org)