Apache Arrow DataFusion 5.0.0 Release
Published
18 Aug 2021
By
The Apache Arrow PMC (pmc)
The Apache Arrow team is pleased to announce the DataFusion 5.0.0 release. This covers 4 months of development work and includes 211 commits from the following 31 distinct contributors.
$ git shortlog -sn 4.0.0..5.0.0 datafusion datafusion-cli datafusion-examples
61 Jiayu Liu
47 Andrew Lamb
27 Daniël Heres
13 QP Hou
13 Andy Grove
4 Javier Goday
4 sathis
3 Ruan Pearce-Authers
3 Raphael Taylor-Davies
3 Jorge Leitao
3 Cui Wenzheng
3 Mike Seddon
3 Edd Robinson
2 思维
2 Liang-Chi Hsieh
2 Michael Lu
2 Parth Sarthy
2 Patrick More
2 Rich
1 Charlie Evans
1 Gang Liao
1 Agata Naomichi
1 Ritchie Vink
1 Evan Chan
1 Ruihang Xia
1 Todd Treece
1 Yichen Wang
1 baishen
1 Nga Tran
1 rdettai
1 Marco Neumann
The release notes below are not exhaustive and only expose selected highlights of the release. Many other bug fixes and improvements have been made: we refer you to the complete changelog.
Performance
There have been numerous performance improvements in this release. The following chart shows the relative performance of individual TPC-H queries compared to the previous release.
TPC-H @ scale factor 100, in parquet format. Concurrency 24.
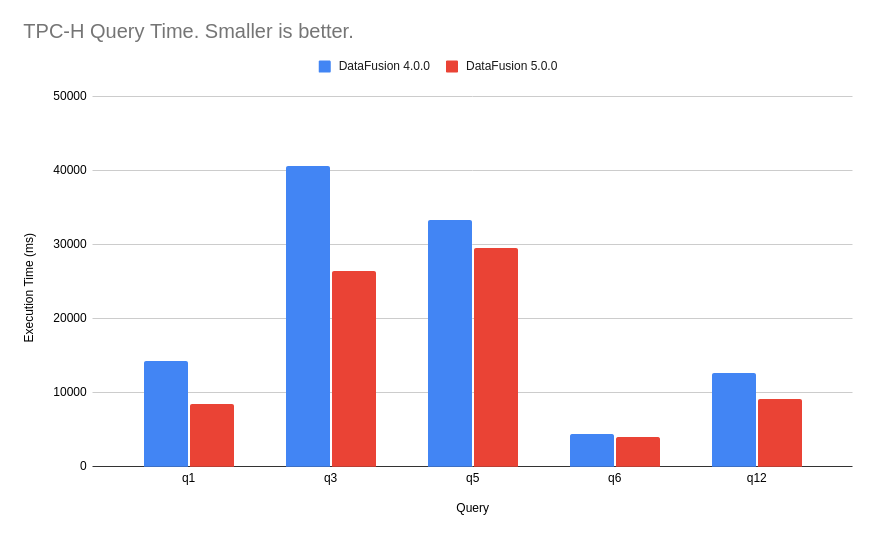
We also extended support for more TPC-H queries: q7, q8, q9 and q13 are running successfully in DataFusion 5.0.
New Features
- Initial support for SQL-99 Analytics (WINDOW functions)
- Improved JOIN support: cross join, semi-join, anti join, and fixes to null handling
- Improved EXPLAIN support
- Initial implementation of metrics in the physical plan
- Support for SELECT DISTINCT
- Support for Json and NDJson formatted inputs
- Query column with relations
- Added more datetime related functions:
now,date_trunc,to_timestamp_millis,to_timestamp_micros,to_timestamp_seconds - Streaming Dataframe.collect
- Support table column aliases
- Answer count(*), min() and max() queries using only statistics
- Non-equi-join filters in JOIN conditions
- Modulus operation
- Support group by column positions
- Added constant folding query optimizer
- Hash partitioned aggregation
- Added
randomSQL function - Implemented count distinct for floats and dictionary types
- Re-exported arrow and parquet crates in Datafusion
- General row group pruning logic that’s agnostic to storage format
How to Get Involved
If you are interested in contributing to DataFusion, we would love to have you! You can help by trying out DataFusion on some of your own data and projects and filing bug reports and helping to improve the documentation, or contribute to the documentation, tests or code. A list of open issues suitable for beginners is here and the full list is here.