Introducing Apache Arrow Flight: A Framework for Fast Data Transport
Published
13 Oct 2019
By
Wes McKinney (wesm)
Translations
日本語
Over the last 18 months, the Apache Arrow community has been busy designing and implementing Flight, a new general-purpose client-server framework to simplify high performance transport of large datasets over network interfaces.
Flight initially is focused on optimized transport of the Arrow columnar format (i.e. “Arrow record batches”) over gRPC, Google’s popular HTTP/2-based general-purpose RPC library and framework. While we have focused on integration with gRPC, as a development framework Flight is not intended to be exclusive to gRPC.
One of the biggest features that sets apart Flight from other data transport frameworks is parallel transfers, allowing data to be streamed to or from a cluster of servers simultaneously. This enables developers to more easily create scalable data services that can serve a growing client base.
In the 0.15.0 Apache Arrow release, we have ready-to-use Flight implementations in C++ (with Python bindings) and Java. These libraries are suitable for beta users who are comfortable with API or protocol changes while we continue to refine some low-level details in the Flight internals.
Motivation
Many people have experienced the pain associated with accessing large datasets over a network. There are many different transfer protocols and tools for reading datasets from remote data services, such as ODBC and JDBC. Over the last 10 years, file-based data warehousing in formats like CSV, Avro, and Parquet has become popular, but this also presents challenges as raw data must be transferred to local hosts before being deserialized.
The work we have done since the beginning of Apache Arrow holds exciting promise for accelerating data transport in a number of ways. The Arrow columnar format has key features that can help us:
- It is an “on-the-wire” representation of tabular data that does not require deserialization on receipt
- Its natural mode is that of “streaming batches”, larger datasets are transported a batch of rows at a time (called “record batches” in Arrow parlance). In this post we will talk about “data streams”, these are sequences of Arrow record batches using the project’s binary protocol
- The format is language-independent and now has library support in 11 languages and counting.
Implementations of standard protocols like ODBC generally implement their own custom on-wire binary protocols that must be marshalled to and from each library’s public interface. The performance of ODBC or JDBC libraries varies greatly from case to case.
Our design goal for Flight is to create a new protocol for data services that uses the Arrow columnar format as both the over-the-wire data representation as well as the public API presented to developers. In doing so, we reduce or remove the serialization costs associated with data transport and increase the overall efficiency of distributed data systems. Additionally, two systems that are already using Apache Arrow for other purposes can communicate data to each other with extreme efficiency.
Flight Basics
The Arrow Flight libraries provide a development framework for implementing a service that can send and receive data streams. A Flight server supports several basic kinds of requests:
- Handshake: a simple request to determine whether the client is authorized and, in some cases, to establish an implementation-defined session token to use for future requests
- ListFlights: return a list of available data streams
- GetSchema: return the schema for a data stream
- GetFlightInfo: return an “access plan” for a dataset of interest, possibly requiring consuming multiple data streams. This request can accept custom serialized commands containing, for example, your specific application parameters.
- DoGet: send a data stream to a client
- DoPut: receive a data stream from a client
- DoAction: perform an implementation-specific action and return any results, i.e. a generalized function call
- ListActions: return a list of available action types
We take advantage of gRPC’s elegant “bidirectional” streaming support (built on top of HTTP/2 streaming) to allow clients and servers to send data and metadata to each other simultaneously while requests are being served.
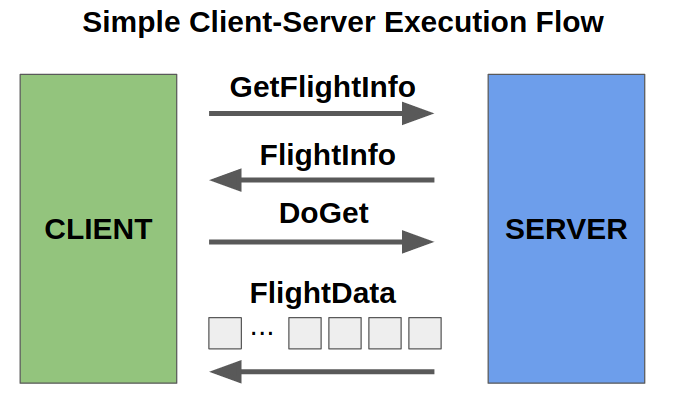
A simple Flight setup might consist of a single server to which clients connect
and make DoGet requests.
Optimizing Data Throughput over gRPC
While using a general-purpose messaging library like gRPC has numerous specific benefits beyond the obvious ones (taking advantage of all the engineering that Google has done on the problem), some work was needed to improve the performance of transporting large datasets. Many kinds of gRPC users only deal with relatively small messages, for example.
The best-supported way to use gRPC is to define services in a Protocol
Buffers (aka “Protobuf”) .proto file. A Protobuf plugin for gRPC
generates gRPC service stubs that you can use to implement your
applications. RPC commands and data messages are serialized using the Protobuf
wire format. Because we use “vanilla gRPC and Protocol Buffers”, gRPC
clients that are ignorant of the Arrow columnar format can still interact with
Flight services and handle the Arrow data opaquely.
The main data-related Protobuf type in Flight is called FlightData. Reading
and writing Protobuf messages in general is not free, so we implemented some
low-level optimizations in gRPC in both C++ and Java to do the following:
- Generate the Protobuf wire format for
FlightDataincluding the Arrow record batch being sent without going through any intermediate memory copying or serialization steps. - Reconstruct a Arrow record batch from the Protobuf representation of
FlightDatawithout any memory copying or deserialization. In fact, we intercept the encoded data payloads without allowing the Protocol Buffers library to touch them.
In a sense we are “having our cake and eating it, too”. Flight implementations
having these optimizations will have better performance, while naive gRPC
clients can still talk to the Flight service and use a Protobuf library to
deserialize FlightData (albeit with some performance penalty).
As far as absolute speed, in our C++ data throughput benchmarks, we are seeing end-to-end TCP throughput in excess of 2-3GB/s on localhost without TLS enabled. This benchmark shows a transfer of ~12 gigabytes of data in about 4 seconds:
$ ./arrow-flight-benchmark --records_per_stream 100000000
Bytes read: 12800000000
Nanos: 3900466413
Speed: 3129.63 MB/s
From this we can conclude that the machinery of Flight and gRPC adds relatively little overhead, and it suggests that many real-world applications of Flight will be bottlenecked on network bandwidth.
Horizontal Scalability: Parallel and Partitioned Data Access
Many distributed database-type systems make use of an architectural pattern where the results of client requests are routed through a “coordinator” and sent to the client. Aside from the obvious efficiency issues of transporting a dataset multiple times on its way to a client, it also presents a scalability problem for getting access to very large datasets.
We wanted Flight to enable systems to create horizontally scalable data
services without having to deal with such bottlenecks. A client request to a
dataset using the GetFlightInfo RPC returns a list of endpoints, each of
which contains a server location and a ticket to send that server in a
DoGet request to obtain a part of the full dataset. To get access to the
entire dataset, all of the endpoints must be consumed. While Flight streams are
not necessarily ordered, we provide for application-defined metadata which can
be used to serialize ordering information.
This multiple-endpoint pattern has a number of benefits:
- Endpoints can be read by clients in parallel.
- The service that serves the
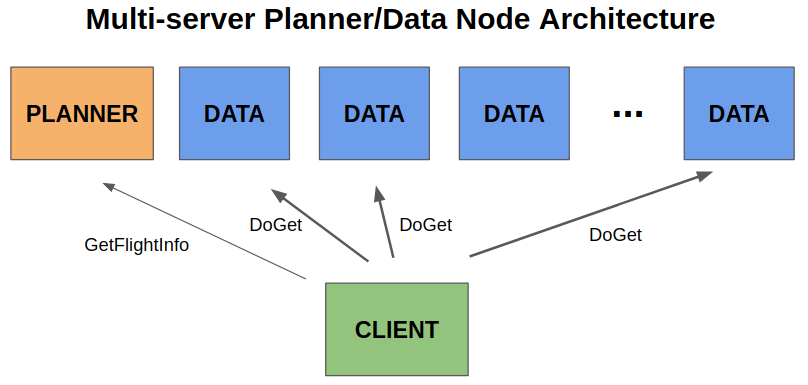
GetFlightInfo“planning” request can delegate work to sibling services to take advantage of data locality or simply to help with load balancing. - Nodes in a distributed cluster can take on different roles. For example, a
subset of nodes might be responsible for planning queries while other nodes
exclusively fulfill data stream (
DoGetorDoPut) requests.
Here is an example diagram of a multi-node architecture with split service roles:
Actions: Extending Flight with application business logic
While the GetFlightInfo request supports sending opaque serialized commands
when requesting a dataset, a client may need to be able to ask a server to
perform other kinds of operations. For example, a client may request for a
particular dataset to be “pinned” in memory so that subsequent requests from
other clients are served faster.
A Flight service can thus optionally define “actions” which are carried out by
the DoAction RPC. An action request contains the name of the action being
performed and optional serialized data containing further needed
information. The result of an action is a gRPC stream of opaque binary results.
Some example actions:
- Metadata discovery, beyond the capabilities provided by the built-in
ListFlightsRPC - Setting session-specific parameters and settings
Note that it is not required for a server to implement any actions, and actions need not return results.
Encryption and Authentication
Flight supports encryption out of the box using gRPC’s built in TLS / OpenSSL capabilities.
For authentication, there are extensible authentication handlers for the client
and server that permit simple authentication schemes (like user and password)
as well as more involved authentication such as Kerberos. The Flight protocol
comes with a built-in BasicAuth so that user/password authentication can be
implemented out of the box without custom development.
Middleware and Tracing
gRPC has the concept of “interceptors” which have allowed us to develop developer-defined “middleware” that can provide instrumentation of or telemetry for incoming and outgoing requests. One such framework for such instrumentation is OpenTracing.
Note that middleware functionality is one of the newest areas of the project and is only currently available in the project’s master branch.
gRPC, but not only gRPC
We specify server locations for DoGet requests using RFC 3986 compliant
URIs. For example, TLS-secured gRPC may be specified like
grpc+tls://$HOST:$PORT.
While we think that using gRPC for the “command” layer of Flight servers makes sense, we may wish to support data transport layers other than TCP such as RDMA. While some design and development work is required to make this possible, the idea is that gRPC could be used to coordinate get and put transfers which may be carried out on protocols other than TCP.
Getting Started and What’s Next
Documentation for Flight users is a work in progress, but the libraries themselves are mature enough for beta users that are tolerant of some minor API or protocol changes over the coming year.
One of the easiest ways to experiment with Flight is using the Python API, since custom servers and clients can be defined entirely in Python without any compilation required. You can see an example Flight client and server in Python in the Arrow codebase.
In real-world use, Dremio has developed an Arrow Flight-based connector which has been shown to deliver 20-50x better performance over ODBC. For Apache Spark users, Arrow contributor Ryan Murray has created a data source implementation to connect to Flight-enabled endpoints.
As far as “what’s next” in Flight, support for non-gRPC (or non-TCP) data transport may be an interesting direction of research and development work. A lot of the Flight work from here will be creating user-facing Flight-enabled services. Since Flight is a development framework, we expect that user-facing APIs will utilize a layer of API veneer that hides many general Flight details and details related to a particular application of Flight in a custom data service.