Faster C++ Apache Parquet performance on dictionary-encoded string data coming in Apache Arrow 0.15
Published
05 Sep 2019
By
Wes McKinney (wesm)
We have been implementing a series of optimizations in the Apache Parquet C++ internals to improve read and write efficiency (both performance and memory use) for Arrow columnar binary and string data, with new "native" support for Arrow's dictionary types. This should have a big impact on users of the C++, MATLAB, Python, R, and Ruby interfaces to Parquet files.
This post reviews work that was done and shows benchmarks comparing Arrow 0.12.1 with the current development version (to be released soon as Arrow 0.15.0).
Summary of work
One of the largest and most complex optimizations involves encoding and
decoding Parquet files' internal dictionary-encoded data streams to and from
Arrow's in-memory dictionary-encoded DictionaryArray
representation. Dictionary encoding is a compression strategy in Parquet, and
there is no formal "dictionary" or "categorical" type. I will go into more
detail about this below.
Some of the particular JIRA issues related to this work include:
- Vectorize comparators for computing statistics (PARQUET-1523)
- Read binary directly data directly into dictionary builder (ARROW-3769)
- Writing Parquet's dictionary indices directly into dictionary builder (ARROW-3772)
- Write dense (non-dictionary) Arrow arrays directly into Parquet data encoders (ARROW-6152)
- Direct writing of
arrow::DictionaryArrayto Parquet column writers (ARROW-3246) - Supporting changing dictionaries (ARROW-3144)
- Internal IO optimizations and improved raw
BYTE_ARRAYencoding performance (ARROW-4398)
One of the challenges of developing the Parquet C++ library is that we maintain low-level read and write APIs that do not involve the Arrow columnar data structures. So we have had to take care to implement Arrow-related optimizations without impacting non-Arrow Parquet users, which includes database systems like Clickhouse and Vertica.
Background: how Parquet files do dictionary encoding
Many direct and indirect users of Apache Arrow use dictionary encoding to
improve performance and memory use on binary or string data types that include
many repeated values. MATLAB or pandas users will know this as the Categorical
type (see MATLAB docs or pandas docs) while in R such encoding is
known as factor. In the Arrow C++ library and various bindings we have
the DictionaryArray object for representing such data in memory.
For example, an array such as
['apple', 'orange', 'apple', NULL, 'orange', 'orange']
has dictionary-encoded form
dictionary: ['apple', 'orange']
indices: [0, 1, 0, NULL, 1, 1]
The Parquet format uses dictionary encoding to compress data, and it is used for all Parquet data types, not just binary or string data. Parquet further uses bit-packing and run-length encoding (RLE) to compress the dictionary indices, so if you had data like
['apple', 'apple', 'apple', 'apple', 'apple', 'apple', 'orange']
the indices would be encoded like
[rle-run=(6, 0),
bit-packed-run=[1]]
The full details of the rle-bitpacking encoding are found in the Parquet specification.
When writing a Parquet file, most implementations will use dictionary encoding
to compress a column until the dictionary itself reaches a certain size
threshold, usually around 1 megabyte. At this point, the column writer will
"fall back" to PLAIN encoding where values are written end-to-end in "data
pages" and then usually compressed with Snappy or Gzip. See the following rough
diagram:

Faster reading and writing of dictionary-encoded data
When reading a Parquet file, the dictionary-encoded portions are usually materialized to their non-dictionary-encoded form, causing binary or string values to be duplicated in memory. So an obvious (but not trivial) optimization is to skip this "dense" materialization. There are several issues to deal with:
- A Parquet file often contains multiple ColumnChunks for each semantic column, and the dictionary values may be different in each ColumnChunk
- We must gracefully handle the "fall back" portion which is not dictionary-encoded
We pursued several avenues to help with this:
- Allowing each
DictionaryArrayto have a different dictionary (before, the dictionary was part of theDictionaryType, which caused problems) - We enabled the Parquet dictionary indices to be directly written into an
Arrow
DictionaryBuilderwithout rehashing the data - When decoding a ColumnChunk, we first append the dictionary values and
indices into an Arrow
DictionaryBuilder, and when we encounter the "fall back" portion we use a hash table to convert those values to dictionary-encoded form - We override the "fall back" logic when writing a ColumnChunk from an
DictionaryArrayso that reading such data back is more efficient
All of these things together have produced some excellent performance results that we will detail below.
The other class of optimizations we implemented was removing an abstraction layer between the low-level Parquet column data encoder and decoder classes and the Arrow columnar data structures. This involves:
- Adding
ColumnWriter::WriteArrowandEncoder::Putmethods that acceptarrow::Arrayobjects directly - Adding
ByteArrayDecoder::DecodeArrowmethod to decode binary data directly into anarrow::BinaryBuilder.
While the performance improvements from this work are less dramatic than for dictionary-encoded data, they are still meaningful in real-world applications.
Performance Benchmarks
We ran some benchmarks comparing Arrow 0.12.1 with the current master branch. We construct two kinds of Arrow tables with 10 columns each:
- "Low cardinality" and "high cardinality" variants. The "low cardinality" case has 1,000 unique string values of 32-bytes each. The "high cardinality" has 100,000 unique values
- "Dense" (non-dictionary) and "Dictionary" variants
See the full benchmark script.
We show both single-threaded and multithreaded read performance. The test machine is an Intel i9-9960X using gcc 8.3.0 (on Ubuntu 18.04) with 16 physical cores and 32 virtual cores. All time measurements are reported in seconds, but we are most interested in showing the relative performance.
First, the writing benchmarks:
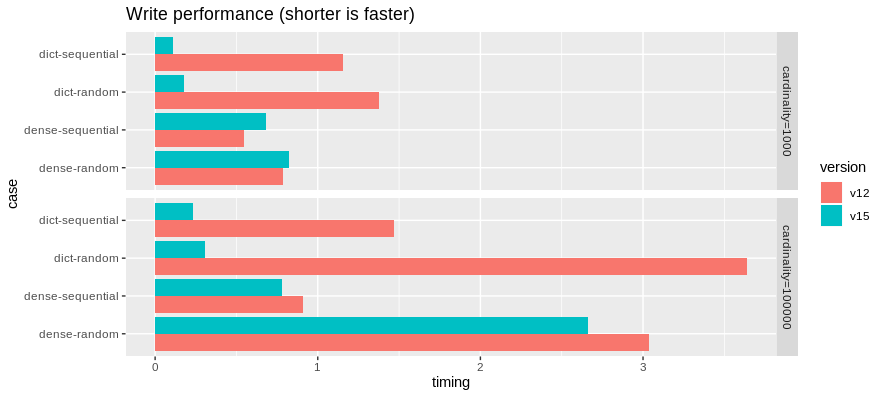
Writing DictionaryArray is dramatically faster due to the optimizations
described above. We have achieved a small improvement in writing dense
(non-dictionary) binary arrays.
Then, the reading benchmarks:
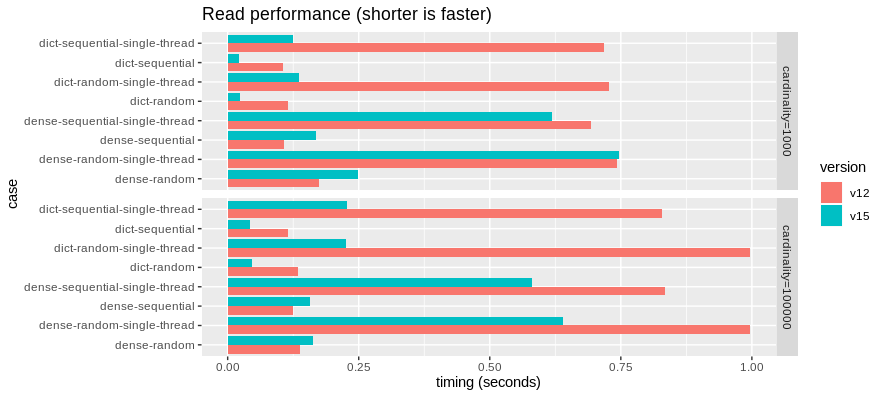
Here, similarly reading DictionaryArray directly is many times faster.
These benchmarks show that parallel reads of dense binary data may be slightly slower though single-threaded reads are now faster. We may want to do some profiling and see what we can do to bring read performance back in line. Optimizing the dense read path has not been too much of a priority relative to the dictionary read path in this work.
Memory Use Improvements
In addition to faster performance, reading columns as dictionary-encoded can yield significantly less memory use.
In the dict-random case above, we found that the master branch uses 405 MB of
RAM at peak while loading a 152 MB dataset. In v0.12.1, loading the same
Parquet file without the accelerated dictionary support uses 1.94 GB of peak
memory while the resulting non-dictionary table occupies 1.01 GB.
Note that we had a memory overuse bug in versions 0.14.0 and 0.14.1 fixed in ARROW-6060, so if you are hitting this bug you will want to upgrade to 0.15.0 as soon as it comes out.
Conclusion
There are still many Parquet-related optimizations that we may pursue in the future, but the ones here can be very helpful to people working with string-heavy datasets, both in performance and memory use. If you'd like to discuss this development work, we'd be glad to hear from you on our developer mailing list dev@arrow.apache.org.