Apache Arrow Flightの紹介:高速データトランスポートフレームワーク
Published
13 Oct 2019
By
Wes McKinney (wesm)
Translations
原文(English)
この1.5年、Apache ArrowコミュニティーはFlightの設計と実装を進めてきました。Flightは高速なデータトランスポートを実現するための新しいクライアント・サーバー型のフレームワークです。Flightを使うとネットワーク越しに大きなデータセットを送る処理を簡単に実現できます。Flightは特定用途向けに設計されたものではないため、幅広い用途で利用できます。
Flightの実装は、まず、gRPCを使ったArrow列指向フォーマット(つまり「Arrowレコードバッチ」)のトランスポートの最適化に注力しました。gRPCはGoogleが開発しているHTTP/2ベースのRPCライブラリー・フレームワークで、広く利用されています。gRPCも特定用途向けではなく幅広い用途で使えるように設計されています。これまでFlightをgRPCベースで実装することに注力してきましたが、gRPCでだけ使えるようにしたいわけではありません。
Flightと他のデータトランスポートフレームワークとの大きな違いは並列転送機能です。クライアントとサーバークラスター間で同時にデータをストリームで転送できます。この機能により、簡単にスケーラブルなデータサービスを開発できます。スケーラブルなデータサービスとはクライアント数が増えても大丈夫なサービスです。
Apache Arrow 0.15.0でC++(Pytonバインディングあり)とJavaでFlightを使えるようになっています。 現時点ではベータユーザー向けです。ベータユーザーとはFlight内部の低レベルの改良によりAPIやプロトコルが変わっても適応できるユーザーのことです。
モチベーション
多くの人がネットワーク越しに大きなデータセットにアクセスすることに関して困っています。リモートのデータサービスからデータセットを読むためのさまざまな転送プロトコルやツールがたくさんあります。たとえばODBCやJDBCです。この10年、ファイルベースでデータを保管することが多くなりました。このときにはCSVやAvroやParquetといったフォーマットがよく使われます。しかし、この方法ではデシリアライズする前に生データをローカルのホストに転送しなければいけないという問題があります。
Apache Arrowの初期からやってきた作業によりさまざまな方法でデータトランスポートを加速できます。Arrow列指向フォーマットには次の重要な機能があります。
- 表形式データの「転送用の」表現です。この表現はデータ受信側でデシリアライズが必要ありません。
- 標準で「バッチをストリーム送信」するためのモードがあります。このモードでは、大きなデータセットを複数の行ごとにまとめて転送します。(Arrowの用語では「レコードバッチ」と呼んでいます。)この記事では「データストリーム」について話します。データストリームとはApache Arrowプロジェクトのバイナリープロトコルを使った一連のArrowレコードバッチです。
- このフォーマットはプログラミング言語に依存していません。このフォーマットは現在11のプログラミング言語がサポートしています。サポートしているプログラミング言語は増え続けています。
ODBCのような標準的なプロトコルの各実装は、通常、それぞれ独自の転送用バイナリープロトコルを実装します。これらのプロトコルは各ライブラリーの公開インターフェイスの表現と相互に変換しなければいけません。ODBC・JDBCライブラリーのパフォーマンスは場合によって大きく異なります。
私たちのFlightの設計で目指していることは、データサービス用の新しいプロトコルを作ることです。このプロトコルは転送用のデータ表現にも開発者向けの公開APIにもArrow列指向フォーマットを使います。こうすることで、データトランスポート関連のシリアライズコストを減らし、分散データシステム全体を効率化できます。さらに、すでに別の用途にApache Arrowを使っているシステム間では非常に効率的にデータをやりとりできます。
Flightの基礎
Arrow Flightライブラリーはデータストリームを送受信できるサービスを実装するための開発者向けフレームワークを提供します。Flightサーバーは次の基本的なリクエストをサポートしています。
- Handshake:クライアントが認証済みかを確認するシンプルなリクエスト。いくつかのケースでは、以降のリクエストのために実装定義のセッショントークンを確立します。
- ListFlights:利用可能なデータストリームのリストを返します。
- GetSchema:データストリームのスキーマを返します。
- GetFlightInfo:対象のデータセット用の「アクセスプラン」を返します。複数のデータストリームを消費しなければいけないかもしれません。このリクエストにはシリアライズしたカスタムコマンドを含めることができます。たとえば、アプリケーション固有のパラメーターを含めることができます。
- DoGet:クライアントにデータストリームを送信します。
- DoPut: クライアントからデータストリームを受信します。
- DoAction:実装依存のアクションを実行し、結果を返します。つまり、一般的な関数呼び出しです。
- ListActions:利用可能なアクションの種類を返します。
gRPCの「双方向の」ストリーミングサポート(HTTP/2ストリーミング上に実装されています)を活用して、リクエスト処理中でもデータとメタデータをクライアント・サーバー間でやりとりできます。
単純なFlightの構成は1台のサーバーとそのサーバーに接続しDoGetリクエストをするクライアントという構成です。
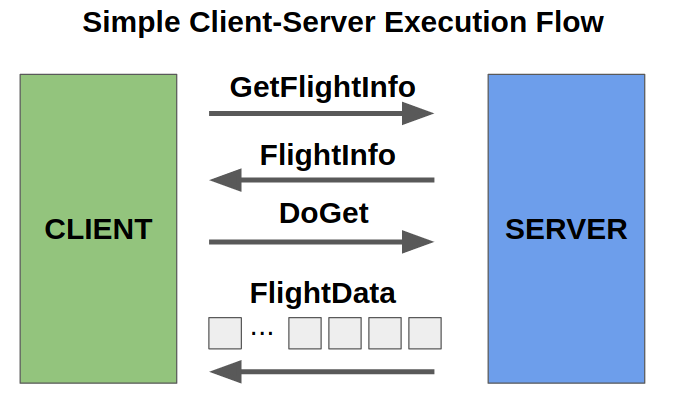
gRPCごしのデータスループットの最適化
gRPCのような汎用メッセージングライブラリーを使うことには多くの利点があります。汎用ライブラリーはすでに多数の問題を解決しているからです。gRPCの場合はGoogleが多数の問題を解決していました。しかし、大きなデータセットのトランスポート性能を改善するためにいくつかの処理を改善する必要がありました。多くのgRPCユーザーは比較的小さなメッセージしか扱っていないからです。
一番よくサポートされているgRPCを使う方法はサービスをProtocol Buffers(「Protobuf」と呼ばれることもあります)の.protoファイルで定義する方法です。gRPCのProtobufプラグインはgRPCサービスのスタブを生成します。このスタブを使ってアプリケーションを実装します。RPCコマンドとデータメッセージはProtobufワイヤーフォーマットを使ってシリアライズします。Flightでは「普通のgRPCとProtocol Buffers」を使っているので、Arrow列指向フォーマットのことを知らないgRPCクライアントでもFlightサービスとやりとりできますし、Arrowデータの中身を気にせずに処理できます。
Flightの中の主要なデータ関連のProtobufの型はFlightDataと呼ばれています。一般的にProtobufメッセージの読み書きにはコストがかかります。そのため、C++でもJavaでもgRPCにいくつか次のような低レベルの最適化を実装しています。
-
FlightData用のProtobufワイヤーフォーマットを生成します。FlightDataには送信対象のArrowレコードバッチが含まれていますが、メモリーコピー・シリアライズ処理は一切ありません。 - Protobufで表現された
FlightDataからメモリーコピー・デシリアライズ処理なしでArrowレコードバッチを再構築できます。実際には、Protocol Buffersライブラリーにエンコードされたデータペイロードを触らせないようにしています。
Protobufを使うがProtobufのメッセージパースのオーバーヘッドはなくしたいという両立できない2つのことを両立させようとしているということです。Flight実装は上述の最適化をして高速化しています。素のgRPCクライアントでもFlightサービスとやりとりできますが、素のgRPCクライアントにはこのような最適化はないので、Protobufライブラリーを使ってFlightDataをデシリアライズすることになります。そのため、素のgRPCクライアントを使うといくらか性能が落ちます。
FlightのC++実装でのデータスループットベンチマークの結果での絶対的な性能ですが、どちらもローカルホストで動いているサーバー・クライアント間のTCPスループットは2-3GB/sを上回っていました。ただし、TLSは無効にした状態です。このベンチマークは約4秒で12GBのデータを転送できることを示しています。
$ ./arrow-flight-benchmark --records_per_stream 100000000
Bytes read: 12800000000
Nanos: 3900466413
Speed: 3129.63 MB/s
この結果から次の2つのことを言えます。1つはFlightとgRPCを使うとオーバーヘッドは相対的に小さくなるということです。もう1つは多くの実際のFlightアプリケーションではネットワークの帯域がボトルネックになりそうということです。
水平方向のスケーラビリティ:並列データアクセスとパーティション化したデータアクセス
分散型のデータベースシステムの多くは「コーディネーター」を通してクライアントのリクエストを処理するアーキテクチャーパターンを使っています。クライアントへのデータセットを複数回転送するという明らかに効率に課題がある点はさておき、巨大なデータセットへのアクセスに対するスケーラビリティの問題もあります。
Flightで次のようなシステムを作れるようにしました。それはこのようなボトルネックに取り組まずに水平方向にスケーラブルなデータサービスを作れるシステムです。GetFlightInfo RPCを使ったクライアントのリクエストは エンドポイント のリストを返します。返ってくる各エンドポイントにはサーバーの位置と チケット の情報が入っています。チケットはデータセットの一部を取得するDoGetリクエストに入れてサーバーに送ります。データセット全体にアクセスするためにはすべてのエンドポイントを処理する必要があります。どのエンドポイントのFlightのストリームから処理しなければいけないということはありません。どのエンドポイントのFlightのストリームから処理しても構いません。しかし、特定の順序で処理するための仕組みは用意しています。その仕組みとはアプリケーション固有のメタデータを使えるという仕組みです。順序の情報はメタデータで表現できます。
この複数エンドポイントパターンにはたくさんの利点があります。
- 複数のクライアントが複数のエンドポイントから並列にデータを読み込めます。
-
GetFlightInfo「プランニング」リクエストを提供するサービスは兄弟サービスに処理を移譲できます。これにより、データの局所性の利点を得られたり、単純にロードバランスしやすくなったりします。 - 分散クラスター中のノードは異なる役割を引き受けることができます。たとえば、クラスター内の一部のノードはクエリープランニングに責任を持つかもしれません。一方、他のノードはデータストリームリクエスト(
DoGetまたはDoPut)だけを処理するかもしれません。
次の図はサービスの役割を分けた複数ノードアーキテクチャーの例です。
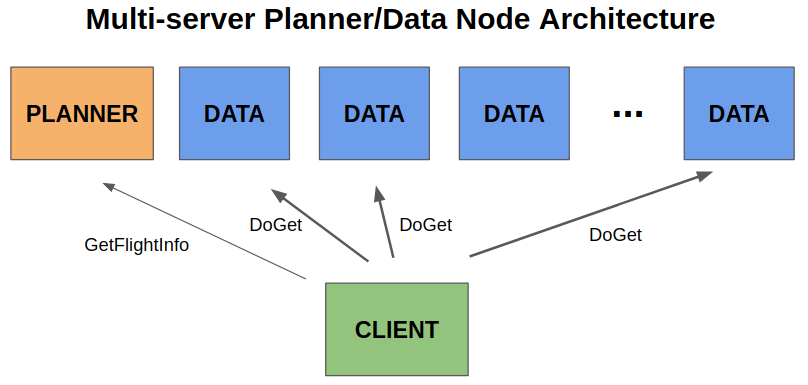
アクション:アプリケーション固有のロジックでFlightを拡張
GetFlightInfoリクエストはデータセットをリクエストするときにシリアライズしたコマンドを中身を気にせずに送ることができますが、クライアントはデータストリームの送受信以外の操作をサーバーに依頼できなければいけないかもしれません。たとえば、クライアントは特定のデータセットをメモリー上に「ピン止め」することを要求するかもしれません。ピン止めすることで他のクライアントからの後続のリクエストを高速に処理できます。
Flightサービスは追加で「アクション」を定義できます。DoAction RPCでアクションを実行できます。アクションリクエストには実行したいアクションの名前と追加情報が入っています。追加情報は省略可能です。アクションの結果はgRPCストリームです。このgRPCストリーム中には任意の結果を入れられます。
いくつかアクションの例を紹介します。
- メタデータを見つけるアクション。組み込みの
ListFlightsRPCでも提供されている機能ですが、ListFlightsの機能で不十分な場合はアクションで実現できます。 - セッション固有のパラメーターを設定するアクション。
サーバーはアクションを1つも実装しなくてもよいことに注意してください。また、アクションは結果を返さなくてもよいです。
暗号化と認証
Flightは組み込みで暗号化をサポートしています。gRPCの組み込みのTLS/OpenSSLの機能を使っています。
クライアント側・サーバー側ともに拡張可能な認証ハンドラーがあります。この認証ハンドラーを使えば、ユーザー名とパスワードのようなシンプルな認証スキーマも使えますし、ケルベロスのような複雑な認証も使えます。Flightプロトコルには組み込みのBasicAuth機能がついています。そのため、追加の開発なしでそのままユーザー名とパスワードの認証を実現できます。
ミドルウェアとトレース
gRPCには「インターセプター」というコンセプトがあります。インターセプターを使うと開発者が定義した「ミドルウェア」を開発できます。ミドルウェアを使うと届いたリクエストと送るリクエストに介在することができます。このような処理をするフレームワークにOpenTracingがあります。
ミドルウェアの機能は最近Flightに追加された機能です。そのため、今のところはmasterブランチでしか使えません。
gRPCを使っているがgRPCだけではない
DoGetリクエストでサーバーの位置を指定する方法にはRFC 3986準拠のURIを使っています。たとえば、TLSを使ったgRPCはgrpc+tls://$HOST:$PORTというように指定します。
Flightサーバーの「コマンド」レイヤーにgRPCを使っているのは妥当だと思っていますが、RDMAのようなTCP以外のデータトランスポート層もサポートしたくなるかもしれません。設計・開発時間が必要になりますが、おそらく、TCP以外のプロトコル上でデータを転送するときでもgRPCを使えるでしょう。
はじめかたと今後の話
Flightユーザー向けのドキュメントは作成中です。しかし、このライブラリーはベータユーザー向けには十分に使い物になります。ベータユーザーとは今後1年で発生するだろう軽微なAPI・プロトコルの変更に耐えられるユーザーです。
Flightをためす簡単な方法はPython APIを使う方法です。なぜならカスタムサーバーもカスタムクライアントもすべてPythonだけで定義できるからです。なにもコンパイルする必要はありません。ArrowのコードにあるPythonでのFlightクライアントとサーバーの例を参考にできます。
実際に使っている例もあります。DremioはArrow Flightベースのコネクターを開発しました。このコネクターはODBCよりも20-50倍よい性能を発揮することを示しました。ArrowのコントリビューターであるRyan MurrayはApache Sparkユーザー向けにFlight対応エンドポイントに接続するデータソース実装を作りました。
最後に今後の話をします。gRPCではない(あるいはTCPではない)データトランスポートをサポートできないか研究開発を進めるかもしれません。Flightの開発が進むとユーザーが使えるFlight対応サービスが増えていくでしょう。Flightは開発フレームワークなので、ユーザーが使うAPIは高レベルなAPIだけになるようにするつもりです。高レベルなAPIではFlightの詳細と特定のFlightアプリケーションに関連する詳細を隠します。