A Native Go Library for Apache Arrow
Published
22 Mar 2018
By
The Apache Arrow PMC (pmc)
Since launching in early 2016, Apache Arrow has been growing fast. We have made nine major releases through the efforts of over 120 distinct contributors. The project’s scope has also expanded. We began by focusing on the development of the standardized in-memory columnar data format, which now serves as a pillar of the project. Since then, we have been growing into a more general cross-language platform for in-memory data analysis through new additions to the project like the Plasma shared memory object store. A primary goal of the project is to enable data system developers to process and move data fast.
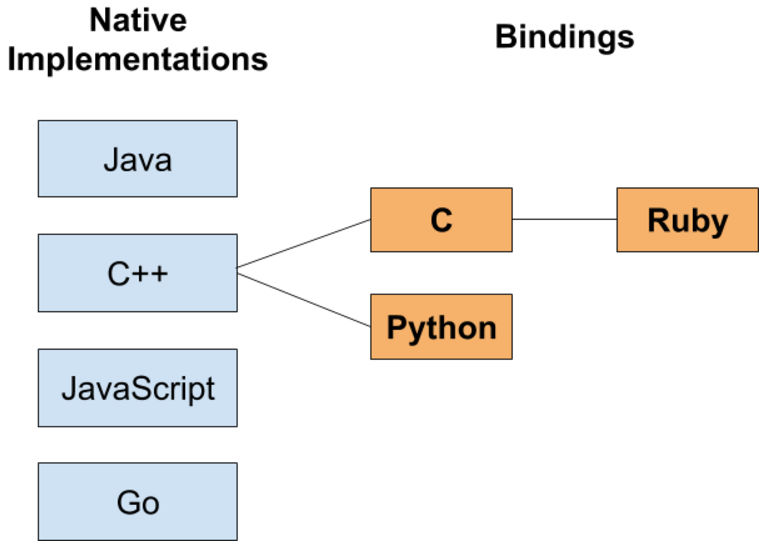
So far, we officially have developed native Arrow implementations in C++, Java, and JavaScript. We have created binding layers for the C++ libraries in C (using the GLib libraries) and Python. We have also seen efforts to develop interfaces to the Arrow C++ libraries in Go, Lua, Ruby, and Rust. While binding layers serve many purposes, there can be benefits to native implementations, and so we’ve been keen to see future work on native implementations in growing systems languages like Go and Rust.
This past October, engineers Stuart Carnie, Nathaniel Cook, and Chris Goller, employees of InfluxData, began developing a native [Go language implementation of the Apache Arrow in-memory columnar format for use in Go-based database systems like InfluxDB. We are excited to announce that InfluxData has donated this native Go implementation to the Apache Arrow project, where it will continue to be developed. This work features low-level integration with the Go runtime and native support for SIMD instruction sets. We are looking forward to working more closely with the Go community on solving in-memory analytics and data interoperability problems.
One of the mantras in The Apache Software Foundation is "Community over Code". By building an open and collaborative development community across many programming language ecosystems, we will be able to development better and longer-lived solutions to the systems problems faced by data developers.
We are excited for what the future holds for the Apache Arrow project. Adding first-class support for a popular systems programming language like Go is an important step along the way. We welcome others from the Go community to get involved in the project. We also welcome others who wish to explore building Arrow support for other programming languages not yet represented. Learn more at https://arrow.apache.org and join the mailing list dev@arrow.apache.org.